

上次我们探讨了数据公司的相关内容,就数据公司而言,我想让大家对数据宇宙不断膨胀的未来形成一种看法,对什么是可能的和什么是不可能的保持某种思辨的好奇心。
数据、模型、人工智能这些概念联系紧密并有部分交叉,它们在云计算时代迎来了新的爆发,比如最近热度极高的ChatGPT,在自然语言处理方面展现的能力达到了极其惊人的地步,其背后是拥有千亿级别参数的极度复杂的语言模型,通过微软的Azure云平台的强大算力来训练模型。
ChatGPT让我们见识了自然语言处理模型的威力,而且通过机器学习,模型不断自我提高其精度,《华尔街日报》有一篇文章的标题是Models Will Run the World(模型将主宰世界)(Cohen, S. a., & Granade, M. w. (2018, August 19). Models Will Run the World. Wsj. https://www.wsj.com/articles/models-will-run-the-world-1534716720),当然标题有点吸睛作用,更主要的含义是指企业的业务从数据驱动转向模型驱动,突出强调模型的作用。
说到模型这个话题,涉及到非常深入的数学问题,我已经思考这个方面很长时间了,这真的很难,我认为我的数学基础很扎实,我读了10年的书才对此有所领悟。
我们之前说过,软件正在吞噬世界,每个公司都应该拥有融合自身业务的个性化软件,通过软件提高业务的效率,并开始积累沉淀数据。而数据是一种新的燃料,我们使用更多的数据,目的是为了让模型产生更好的结果,然后做出更有价值的分析和预测。但请记住,在过去,对于统计分析、人工智能、机器学习,我们只有数量非常有限的模型。
我认为线性回归是一个很好的模型。实际上,它可能解决了80%的建模问题,唯一的问题或许就是用得太频繁了。线性模型倾向于描述与宇宙的关系。现在我们都知道,每一次模型突破都是人类文明的一次突破,这就是为什么模型如此火爆的原因。请注意,我们现在差不多只有40到50个模型,大数据在这些模型下运行,目的是为了让这些模型获得更好的结果。
现在的问题是,我们可以像艾萨克•牛顿构建经典力学模型那样,创建一个突破性的新模型吗?亦或像诺贝尔奖得主约翰•纳什建立的博弈论模型,又比如马文•明斯基利用很多其他模型构建了一个神经网络模型。这是一个非常有限的模型,但它可以进行拓展模型,我们意识到了模型的优势。
值得注意的是,如果要在某个领域有所突破,就必须是根本性的转变。我们看到,那些突破性的模型基本上是通过数学语言描述的。

比如说,早期有这么一个模型描述自由落体:重物体总是比轻物体下落得快。它没有使用数学语言,是来自亚里士多德的论断,不过,如上图所示,我们使用数学语言将其表述形式化为t = f(m,h)这样一个函数关系式,t表示重物下落的时间,它与物体质量m和物体位置高度h有关。当然,现在我们知道自由落体的时间与物体质量无关,可能因为你总是看到,很重的物体到达地面的时间是一样的,实际上你建立了一个不同的模型,或许你由此会说,当物体很重时,亚里士多德给出的模型不成立。
事实上,在有空气作为介质的环境中,亚里士多德也许是对的,因为如果物体像羽毛一样轻,那么自由落体时间就真的与质量有关,但对于重物体,质量的影响通常可以忽略不计。后来,伽利略运用数学推理和实验结合的方式重构了模型,摒弃了物体质量对自由落体的影响。
你可以看到,使模型合理化的模式更像是一种抽象,讨论了前面两个模型,我们可以继续思考构建新的模型,艾萨克•牛顿建立了新的模型——万有引力定律。它可以解释,物体到达地面的时间与重力有关,而重力与地球的质量和半径有关。
因此,你可以看到,每个模型都可以由其他的模型来解释。所以,模型很像一个公理体系,可以由公理推出各种命题,但公理本身难以由其他命题推出,公理意味着你也不能用其他公理来合理地解释它,你只能接受它。但随着研究的深入,因为我有物理学的背景,我理解物理学的目标是实现对自然的公理化描述,对于自然的组成结构,我们提出几个假设,然后我们构建一个模型,我们预测宇宙的未来,我们通常会进行观察,对结果进行验证,如果结果得到验证,我们将修订我们的模式或假设。
我想大家已经明白了,想想艾萨克•牛顿的力学公式,牛顿的论点并不是单纯关于万有引力定律的,而是关于我们如何运用数学方法来理解自然哲学。所以他写了这本《自然哲学之数学原理》的传世之作,他真的告诉我们如何数学化描述自然。但不知道牛顿是否有思考过——数学还可以预测未来,这是一个非常重要的问题,如果我们运用数学构建各种更复杂更先进的模型,给予模型足够的输入,它们就能告诉我们未来。
为什么?
简单地说,如果用一种文艺的说法——这是上帝使用的语言,上帝有一种非常通用的数学语言。当然,数学在科学领域的运用,自有一套合乎逻辑的理论。
数学在物理领域的运用非常成功,近乎完美的形式化物理定律,并通过实验得以反复验证。
现在,我们来谈谈社会科学方面。在我年轻的时候,往往忽视社会科学,我觉得社会科学缺乏定量特性。但自然科学之外,数学仍然得以运用,就像在博弈论中一样,经济学非常适用于数学化,所以数学化在微观经济学和宏观经济学方面取得了一些突破。
但经济学之外,社会科学真的很难定量化地去研究,社会科学的数学化实际上是人工智能的一门分支学科。
我毕业于卡耐基梅隆大学,很多年之前该校计算机科学系的系主任司马贺应该会认同这种看法,他创立了计算机科学系,他拥有社会科学领域的背景。他问了一个问题,我们如何组织行为,我们如何在此基础上建立模型。对于社会科学来说,数学化困难重重,司马贺意识到,数学化不太适用于社会科学建模。除了博弈论以外,除经济学以外,在其他领域中不是很成功。我们如何预测社会中的其他行为,我们如何预测个人的行为,这是一个人工智能的分支学科,所以他意识到,计算模型是一个很好的工具,一个对社会科学和个人行为进行建模的好工具。
那么,问题来了,如果用计算机对社会科学和个人行为进行建模,那么人类和机器在何种程度上是等价的?我们是一个有机体,我们在何种程度上和机器的模型是等价的,若无等价之处,此等建模,又意义何在?
这就是我们正在思考的问题。
嗯——,两者的行为差异巨大,自然不具等价性,但人类行为受思维支配,当然,我们目前还不能说机器具备思维,但若形式化地去解构思维,这里只看逻辑思维,我认为在两个层面上,机器和有机体是等价的,那就是逻辑和算术。 至于创造性思维及情感,我们不知道它来自哪里。
所以,我想人类绝大多数的思维都是逻辑思维,人类可以进行逻辑推理,人类可以做算术,我强调一下,这里说的不是数学,是算术。而逻辑推理和算术可以通过CPU或芯片的功能电路来构建。真的非常兴奋,这将把所有人类的思维解构到最低程度,剩下逻辑推理和算术,机器可以模拟这两件事,事实上,机器非常擅长这两件事。所以图灵建造的机器只做这两件事。

图灵实际上建立了一个理论计算机,计算机的概念,但图灵实际上并没有发明计算机,但他确实为哲学家创造了一个计算机的雏形。图灵机必须做这两件事,逻辑运算和算术运算,机器模仿人的左脑和右脑,所以它模仿了人类的思维,做一点逻辑运算,做一点算术运算。图灵通过思想实验的方式,他假设自己只是做逻辑和算术运算,然后模拟机器的运作,这真是一种非常有趣的实验方式,你也可以尝试把自己想象成一台机器,将你的能力降低到最低限度,你只做逻辑和算术思考。那么,现在的问题是,我们如何通过处理器的能力,将所有的人类行为转换成逻辑思维和算术能力?
图灵提出了一个大胆的论点,他说,就这种古老的能力而言——逻辑和算术,人类和机器是等价的。他没有说如何将人类的所有思维转换为逻辑和算术运算,但他证明了同一台机器有局限性,有些事情是机器无法胜任的。比如,你能写一个程序检查其他程序是否会进入无限循环吗?比如,你能找到一种方法来检查一个数学公式是否可以被证明吗?你做不到,没有这样的解决方案。图灵认为,人类的思维最终都可以归结为逻辑和算术思维,对于一个人类无法证明的数学公式,机器无法找到一种方法来完成一个筛选这类数学公式的运算。所以他认为机器做不到,人类也做不到。这就是著名的邱奇-图灵论题。
类似内容的探讨也出现在许多电影之中,比如《机械姬》,影片中涉及图灵测试及对人工智能和人类异同的探讨。
我们是如何提出这个伟大的想法——将人类的思维解构并限制到逻辑和算术的最低限度的?现在,我们可以再次提问,为什么我们只检验逻辑?如果你不合逻辑,我不合逻辑,那么我们就无法沟通,因为无论我得出什么结论,你都不会接受它。
所以这是我们内在的东西,我们有逻辑和算术思维。那么,我们是如何走到这里的呢?在漫长的数学史上,有一个著名的数学家叫大卫•希尔伯特,他试图创建一个只使用公理的数学系统,然后通过这些逻辑和算术公理,数量再次受到限制,比如不超过2个公理。他假想自己是一台机器,他只做两种运算,即逻辑和算术运算,他认为可以在此基础上推导出所有的数学公式,然后他发明了一个叫做形式系统的概念,而机器可以重复前述过程。
这就是灵感的来源,所以大卫•希尔伯特提出了这个问题,然后艾伦•图灵建造了这台机器,图灵在论文中构造了一个图灵机来计算可计算数,最终证明希尔伯特提出的通用可判定性方法不存在。如果你探索的问题被证明永远都无法解决,那就是你不应该把你的一生都花在这个问题上,因为它没有解。图灵通过构建机器给出了证明结果,机器无法解决的问题,他认为人类也做不到。
为什么会这样?
我们前面已经讨论过了,在逻辑和算术的层面,我认为机器和人类有等价性。
图灵构建机器并完成了伟大的工作,现在他只给了我们否定的答案,他告诉我们机器无法解决什么问题。但我们可以换种方式来提出另一个问题,既然都说到机器和人类在逻辑和算术层面有等价性这个份上了,那么,人类能做的事情,特别是脑力工作方面,机器能做到吗?亦或能否比人类做得更快更好?
像今天的自动驾驶、人脸识别及ChatGPT等等,机器的表现丝毫不逊色于人类,机器是如何做到的?
问题的答案,寻根问源的话,还是需要在逻辑和算术的层面,来看看这个今天称为人工智能的领域,我们的先驱是如何起步的。
人工智能的起源,一般认为是1956年达特茅斯会议,而该会议的前一年,1955年,Session on Learning Machine (学习机讨论会)的主持人是神经网络的鼻祖之一皮茨(Pitts),他最后总结时说:“(一派人)企图模拟神经系统,而纽厄尔则企图模拟心智(mind)……但殊途同归。”这预示了人工智能随后几十年关于“结构与功能” 的两条进路,可以简单理解成人工智能符号和神经网络两大学派。
卡内基梅隆大学的司马贺和纽厄尔,两位图灵奖得主,是人工智能符号学派的代表人物,他们使用符号,符号是非常形式化的语言,非常方便机器做逻辑和算术运算。机器看到一个符号,就会执行一件事,然后看到另一个符号就会执行另一件事。所以你的直觉是,只是给机器一堆符号,然后通过这些符号给机器的逻辑和数学运算编程,以模仿人类的逻辑和算术运算行为。因此,他们最初尝试解决国际象棋问题,并且一开始就取得了相当大的成功。当然,你应该意识到,一个人大脑中,我们确实处理很多很多符号,大量的符号,这可不是一个小的符号集,通过机器来模仿的难度可想而知。
而另一个流派,神经网络,图灵奖获得者马文•明斯基(Marvin Minsky)建立了另一个更准确的模型。他的模型很有趣,他模仿了人类的大脑结构——神经元,他们建立了一个神经网络。
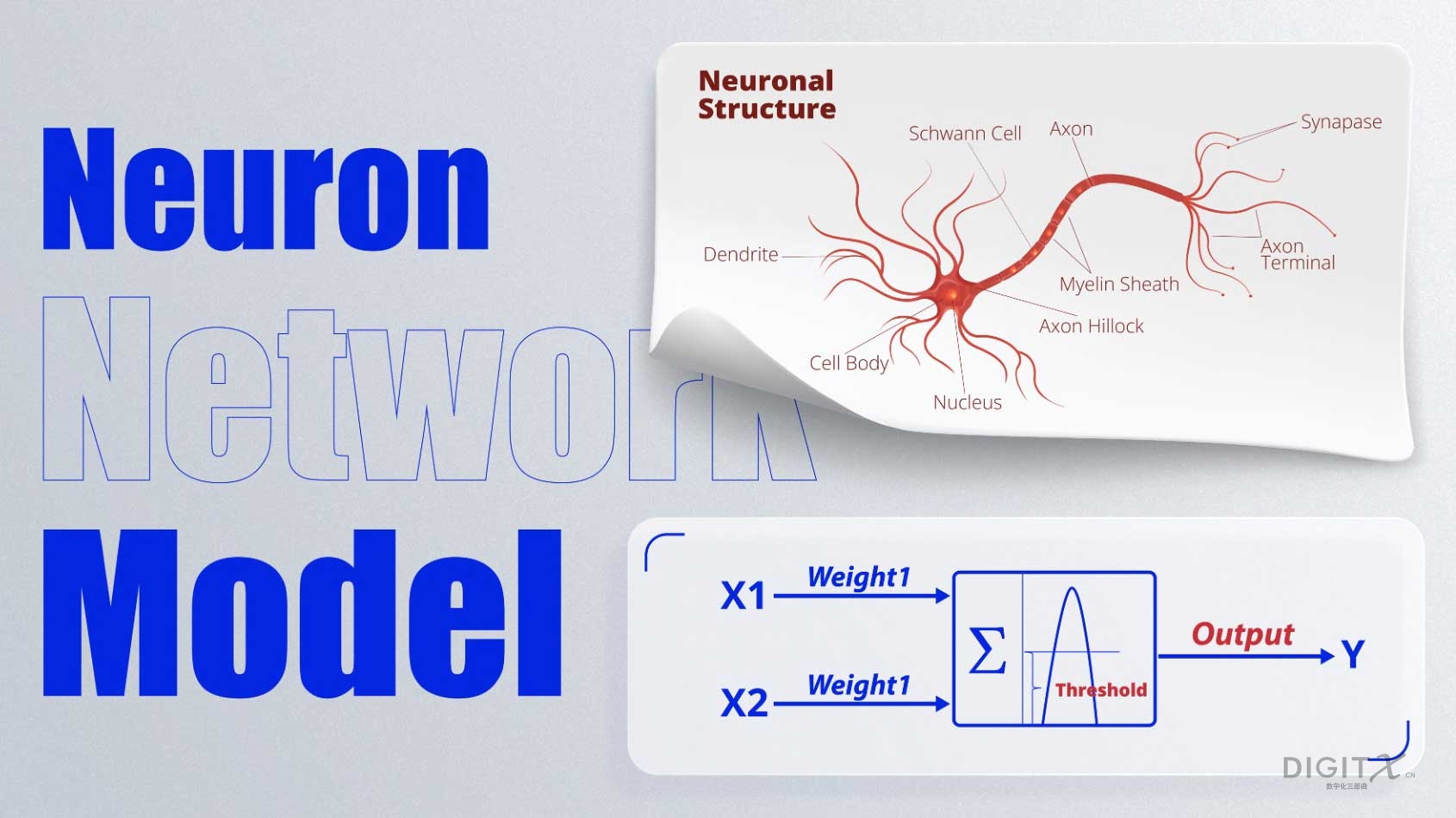
神经元接受两个输入,如果通过组合的输入超过阈值,那么你就有一个向上的输入,然后进入下一个神经元。
这就是我们面部识别、自动驾驶汽车等人工智能模型的基础,但这个模型最终,当你构建神经网络时,将其分解为算术和逻辑运算,因为这是机器可以正常执行的。
现在我们在模型上取得了一些成功,我可以通过模型使机器越来越接近人类,因为我们可以将人类解决问题的技能转化为逻辑,而逻辑是运算是机器擅长的。
现在我们可以大胆假设,我们是否可以由一个程序来自己编写另一个程序,然后程序会接受数据。因为我们提供了大量的数据,程序读取了这些数据,所以程序会自行求解。然后程序将变得更像人。比如,你操作无人机,无人机飞行时,一般来说,无人机基本上只有非常有限的控制参数。无人机可以上下左右移动,我没有操作过无人机,但大家应该有人操作过。如果没操作过无人机,也可以对照一下汽车的驾驶操作,汽车有左转、右转、刹车、油门,控制功能并不是很多。所以无人机实际上是手动飞行的,我们只是给他们很多数据,数据被标记了。当我们输入数据时,这些参数被设置好了,然后无人机就知道这是在下降,它会注意到与其他数据集的组合,通过如此反复及大量数据的训练学习,它就能判断何时该调整到哪种飞行模式。所以无人机不会自己写数据集,它需要海量的数据来调整飞行模型的参数,从而改变程序本身,然后它就知道如何飞行了。
所以我想说的是,程序本身也可以改变。你可以这样想,大量数据通过人类的感官输入大脑,然后大脑会因为某种原因改变我们的行为,是不是和模型通过数据训练学习的过程非常相似。
但问题是,帮助我们学习阅读、学习第一语言、学会骑自行车的根本问题是什么?我们出生的时候,我们就有了这个。现在这个主程序的确创造了所有其他的程序,在各个不同的领域。所以我们正在努力追求的这个问题的答案,我们称之为主算法。
这些是我们正在探索的领域。所以我们创建了数据计算平台,因为这是一个数据计算问题,而从计算平台来看,我们迈入了云时代,云计算使得一切发生了前所未有的改变。在云上,我们拥有接近无限扩展的存储空间和计算资源,我们可以向云平台发送海量的数据来训练模型,然后生成另一个程序,然后在模型的自我学习中日趋完善。想想汽车公司的例子,我们是如何做到的。因为每次汽车故障时都会发送传感器的数据,然后对数据进行标记,然后模型通过这些海量的数据不停地学习训练,调整参数,优化自身,在汽车的整个生命周期中,汽车系统实际上知道什么时候可能会出现故障,或者说出现故障的数据集序列是什么,它每天都会变得更智能。
随着时间的推移,这些持续自我学习训练的人工智能模型,越来越智能,越来越强大,甚至不少科学家担心它们总有一天会超越人类。所以,掌控这些人工智能技术的组织或机构,着实拥有一种过于强大的能量或权力。因此,我们希望这种权力保留在非营利组织,若被一家商业公司掌控,则太危险了。
基于此,我们认为数学公司在安全范围内使用AI模型来提升业务,而强大的AI模型,应该由非营利的数学组织(不是公司)来掌握。我们建立了公益性的数字产业基金会和CMU上海校友会,助力企业的数字化转型和大数据、人工智能等数据计算的相关公益性研究。

所以我们做了很多结对编程,像Pivotal 帮助通用电气、福特建立数字化应用时采用的方式。对于未掌握数字化技术的人,对于没有机会接受正规教育的人,他们可以参加我们基金会的数字化项目,我们可以通过结对编程帮助他们学习数字化技术,帮助他们成为数字工作者,这非常重要,我们也给予数字化转型的企业指导和帮助。后续,我们打算持续推进数字技术社区的建设,建设开源代码库,促进数据科学、数字技术惠及更多的企业、组织和个人。

但最重要的是,当企业数字进化步入数学(AI模型)公司阶段,正如我们前面所讨论的,先进的模型将提供给我们更具突破性的帮助,但在建模的过程中,我认为我们不会找到终极主算法的属性,不过我觉得我们会越来越接近主算法。模型会像一个孩子一样成长,创造其他的程序,然后自我学习。在这个方面,我们的公益基金会,主要与中国的卡内基梅隆大学社区合作,以支持基础人工智能研究,期望它作为一个非营利组织来运营。
在企业数字进化三部曲的末尾部分,我们讨论了对自然进行数学化描述的内容,它为工业革命创造了巨大的成功。在社会科学的数学化讨论中,除了经济学,我们认为社会科学很难数学量化分析,所以我们使用了不同的方法——数据计算,跨入了人工智能模型的领域,但计算是建立在两个基本要素之上的,人类和机器的共有属性是逻辑和算术运算。机器很强大,也有很多能力上的局限性,图灵认为,人类与机器有着同样的局限性。但我们终究愿意相信,人类在创造力上更胜一筹,我们将驾驭人工智能模型,赋能于数字经济、教育、科研、卫生医疗等各个领域,造福人类社会。
—连载完—
( 冯雷(Ray)及数字化三部曲团队原创连载作品,欢迎继续关注。)
Ray和他的数字化三部曲团队
—————————————
冯雷 Ray Feng:
数字化三部曲系列著作主编及首席作者
PieCloudDB Database eMPP存算分离云原生数据库总设计师
1024数字产业基金会理事长
卡内基梅隆大学上海校友会主席
拓数派创始人兼首席执行官
数字化三部曲团队:
致力于企业——软件公司 → 数据公司 → 数学(AI模型)公司的数字化三部曲方法及软件代码级别架构实践真实落地