在《大模型数据计算系统——理论》部分,我们谈到数据计算系统通过原生计算规则,并通过引入初始模型和数据进行训练,将训练好的模型作为一个新的计算规则引入到数据计算系统中。我们在纵向上无限逼近终极模型,在横向上创造更大的模型。因此,大模型数据计算系统的数字智能不断提升,成为新的生产力,推动GDP持续发展,提供新的经济增长。
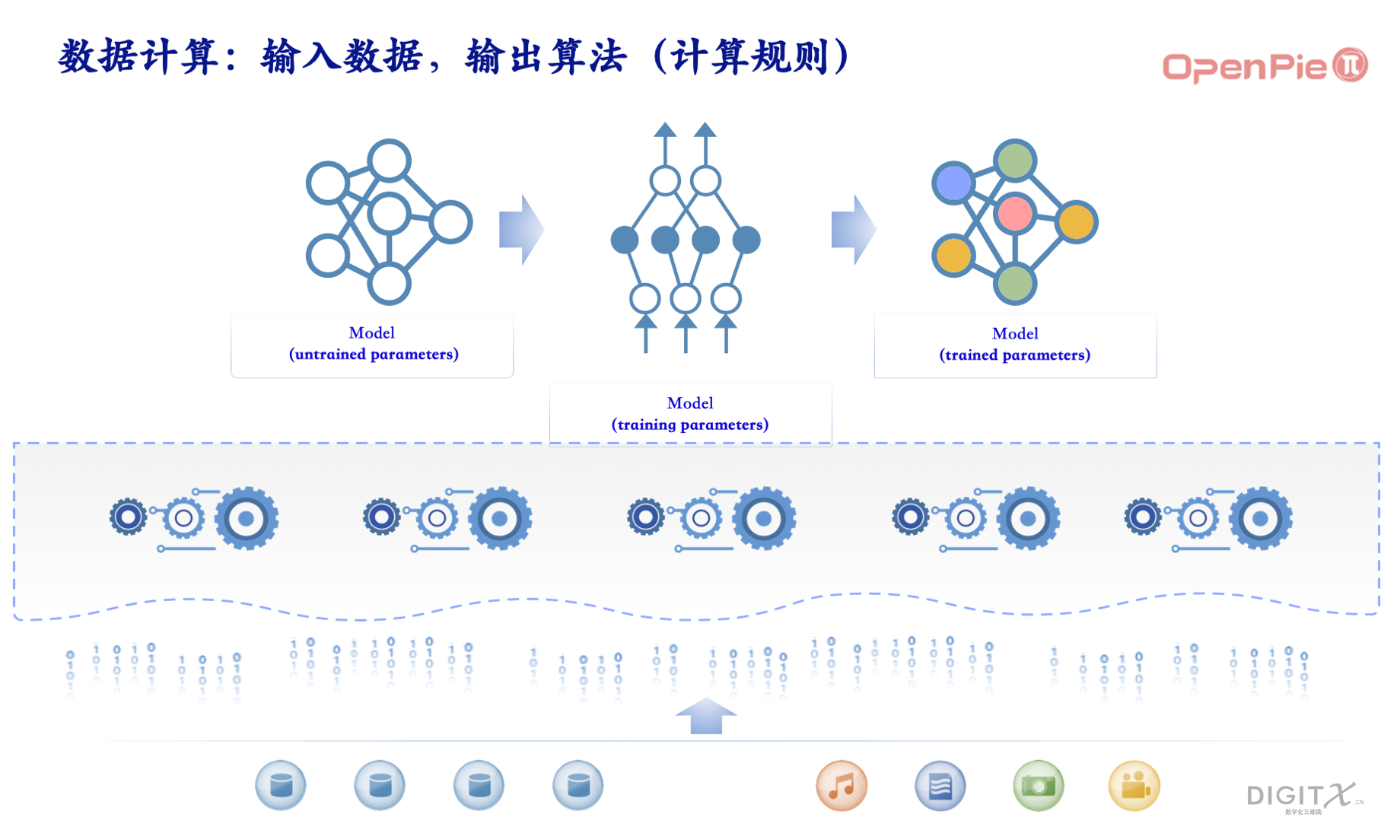
这套系统的设计目标基本如上图,我们通过数字化将大千世界的现象和运动形成数据,存储在系统的底部。这个系统通过建模的方法输入没有训练的初始模型,在系统中对数字化形成的数据进行训练,输出训练好的模型,作为新的计算规则引入到系统中作为局部公理。接下来,我们将讨论这套系统的物理实现,从这里开始,计算需要用图灵机来理解,而不是理论探讨时候用的λ(lambda)演算。
在展开拓数派的大模型数据计算之前,我们先概览一下拓数派在1024上宣布的最终产品系列:
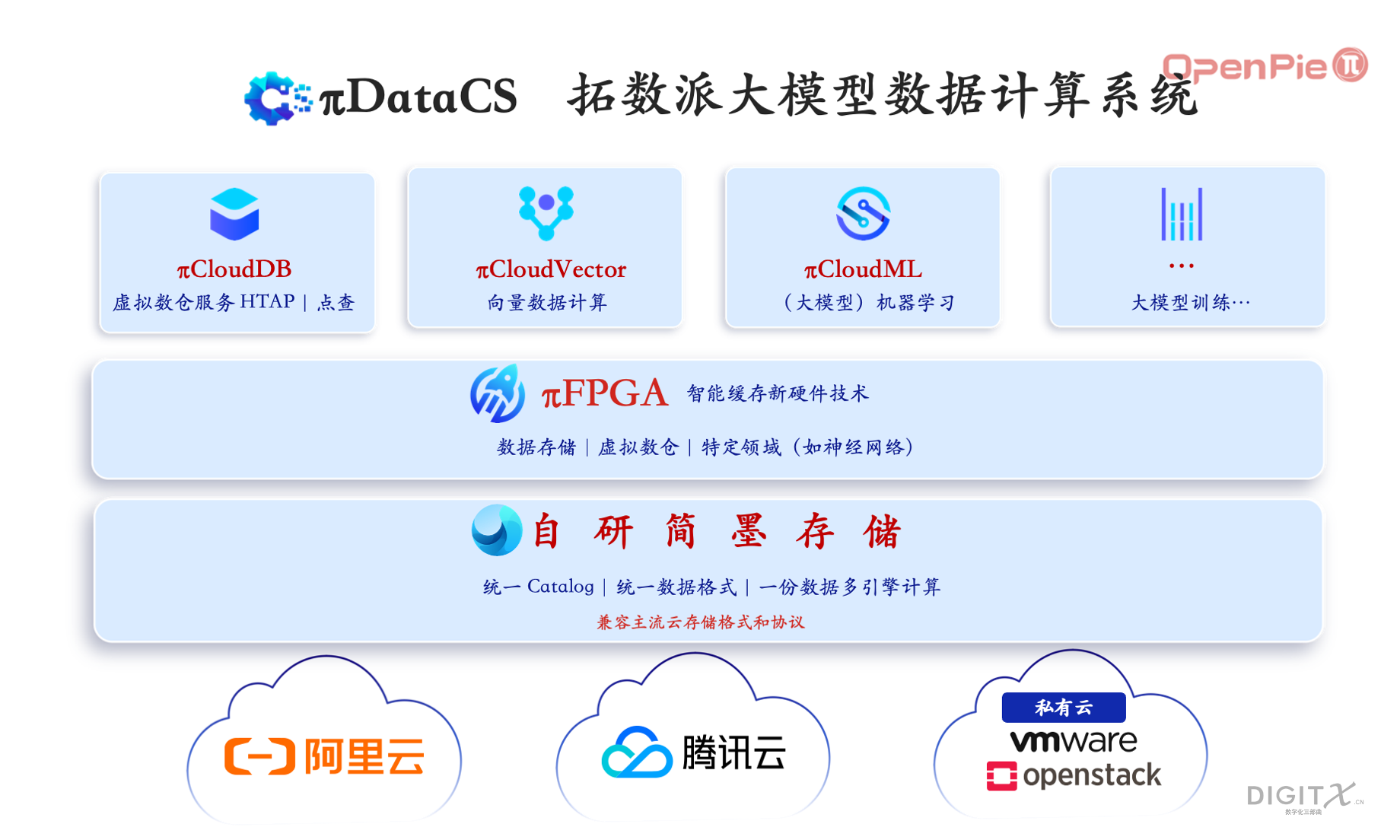
在上图这个系统中,包括了数个行业最顶级的硬核软件和硬件技术创新:
- 为支持SQL语言模型建立的云原生数仓计算引擎πCloudDB(PieCloudDB),兼容HTAP
- 为支持和大模型配合的向量计算而建立的云原生向量计算引擎πCloudVector(PieCloudVector)
- 为支持Python和R的机器学习语言而建立的云原生机器学习引擎πCloudML(PieCloudML),兼容湖仓一体
- 对于超大基础模型训练,需要数据拥有者和计算资源拥有者配合,拓数派愿意和行业伙伴一事一议
- 这些计算引擎共享一个数据存储底座——简墨,实现一份数据,多引擎计算。简墨的目标是成为来自于中国的基于Table Format的世界级存储标准
- 为了弥补云上存算分离的性能损失,我们海外部署LTL实验室,实验室科学家秘密研发了两年的πFPGA新硬件技术,实现云上存储向计算传输的性能高于本地硬盘。πFPGA本身也是AI技术,根据计算的需要,提前从云存储中准备好数据到本地缓存。
接下来,我们将一步步解析拓数派团队是如何通过简单的设计原则来驾驭这套复杂的系统。为了支持当代的最大模型能力,拓数派选择从云原生开始架构大模型数据计算系统。计算平台从大型机、PC机到如今的云平台经历了三代大的变更。云平台代表了目前最大的计算能力、存储能力和水平扩展能力。虽然云计算已经存在了近20年,但当代数据工具和平台大部分还是针对PC架构设计的,它们在云上处于被向下兼容模式,属于逆大模型技术。作为原生理念最早的提出者和实践者,拓数派果断摒弃了PC时代的技术,甚至是自己的早期基于PC架构的作品。
由于云上环境的物理服务器通常不带有本地硬盘,而是通过块存储形成云盘和S3存储形成海量存储。拓数派选择把数据计算系统中的计算和数据分离,考虑到未来数据治理和交易,拓数派把数据中的元数据和用户数据再次分离。
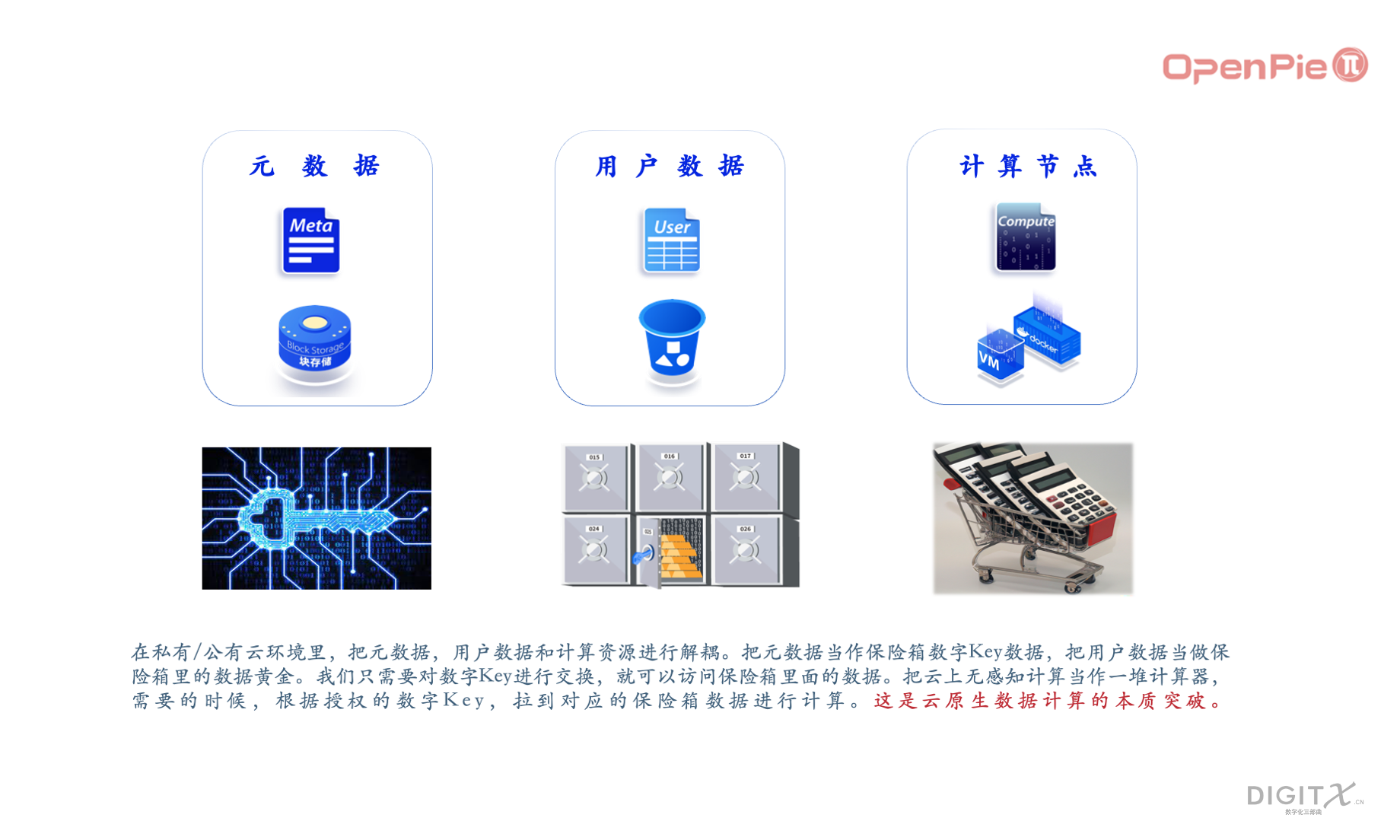
在私有/公有云环境里,把元数据、用户数据和计算资源进行解耦。把元数据当作保险箱数字Key数据,把用户数据当做保险箱里的数据黄金。我们只需要对数字Key进行交换,就可以访问保险箱里面的数据。把云上无感知计算当作一堆计算器,需要的时候,根据授权的数字Key,拉到对应的保险箱数据进行计算。这是云原生数据计算的本质性突破。
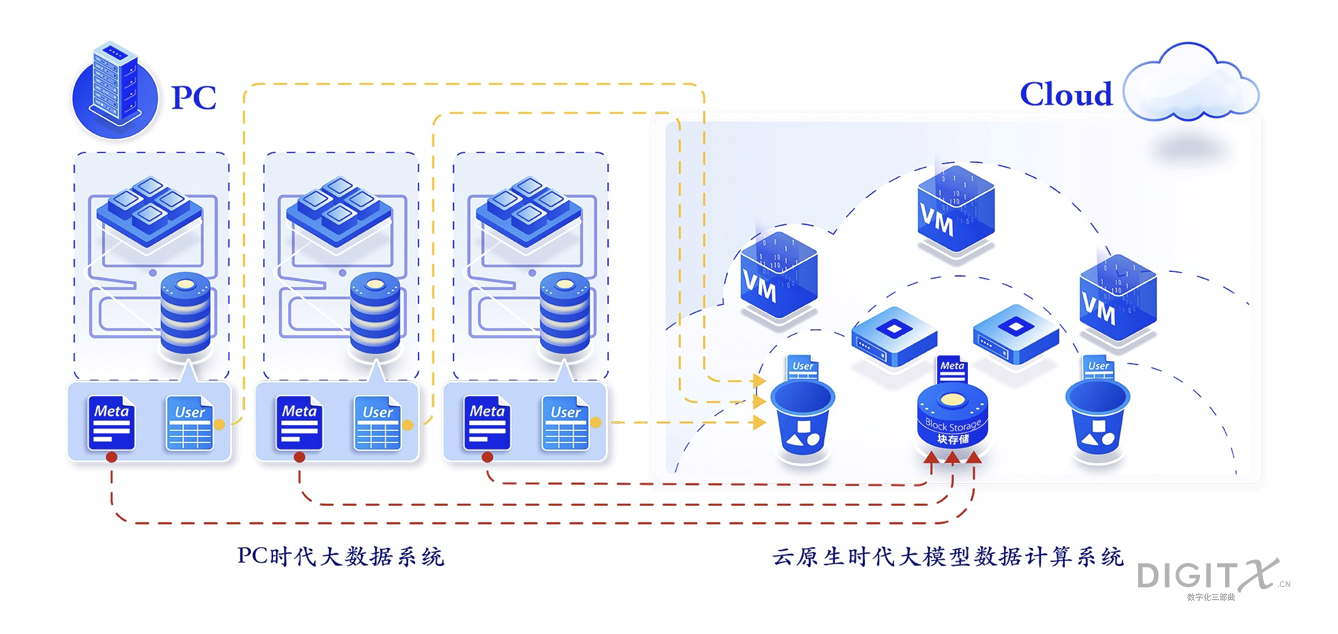
在PC结构中,元数据和用户数据映射在本地硬盘,计算映射在本地CPU,它们都紧紧耦合在同一个服务器上。拓数派对这种结构进行拆解,把元数据映射到块存储,由我们的木渎系统来管理,把用户数据映射到对象存储,由我们的简墨来管理,把计算映射到容器或者虚拟机,由我们的计算系统来管理。
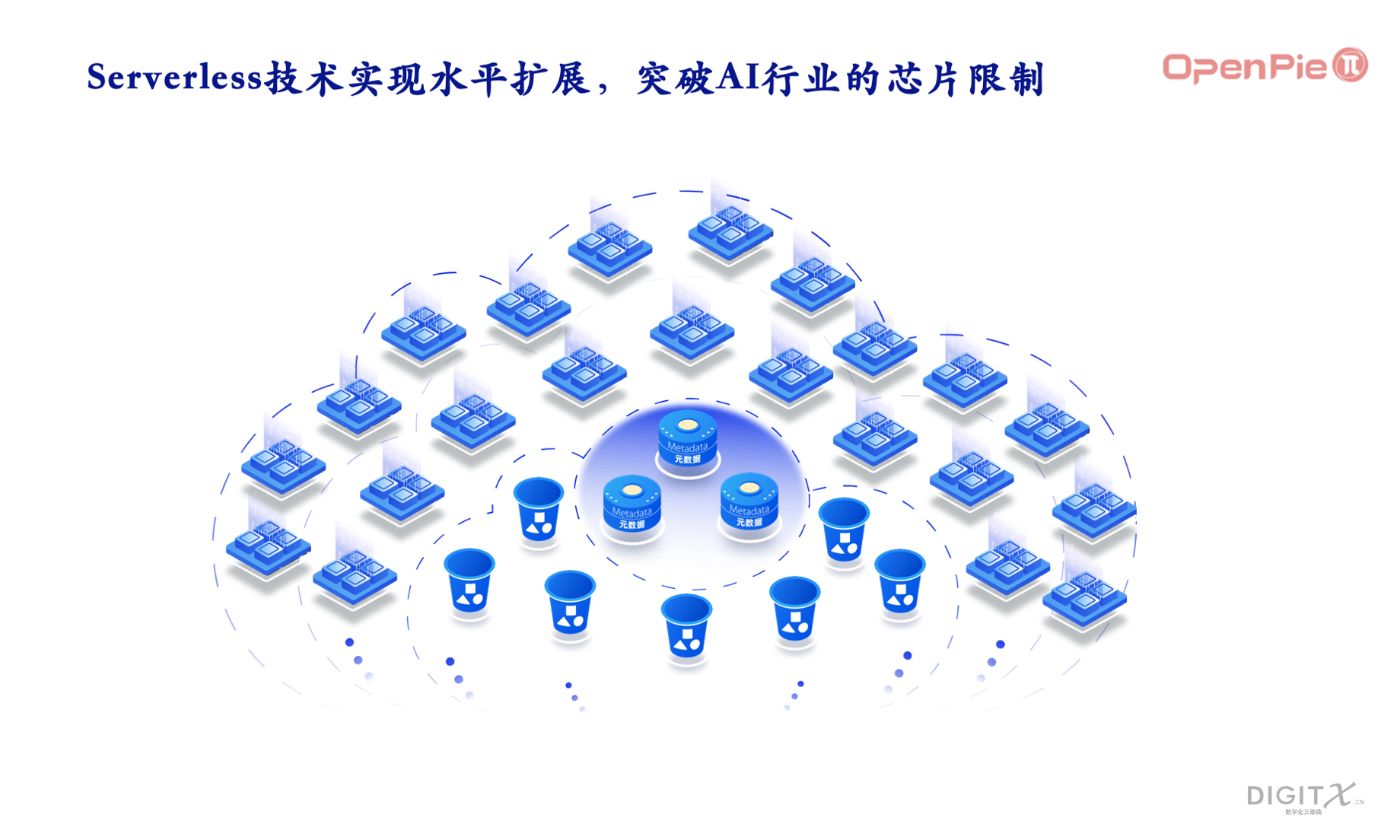
由于私有云/公有云的容器或者虚拟机可以动态增减,拓数派的任何一个计算引擎都可以根据模型计算的需要动态增加或者减少容量。假设有一个中等大小的模型,需要用100台虚拟服务器计算800小时,那么在拓数派的数据计算系统中,就可以寻找800多台虚拟服务器把时间降低到100小时左右。读者可以看到,这种横向扩展的方法,提供了芯片计算能力纵向扩展的另外一种方式,从而可以绕开一些芯片的限制。
拓数派的数据计算系统深入考虑了全球数据交易和数据治理的要求。数据作为一种新的生产要素,是模型发展的重要燃料。在隐私和安全的前提条件下,数据所有者可以把含数据目录的元数据对数据经营者公布,数据经营者通过元数据来访问所有者的用户数据,并根据需要,通过授权来有偿访问所有者的用户数据。数据经营者在访问所有者的数据的时候,需要调用数据加工者提供的数据计算引擎。
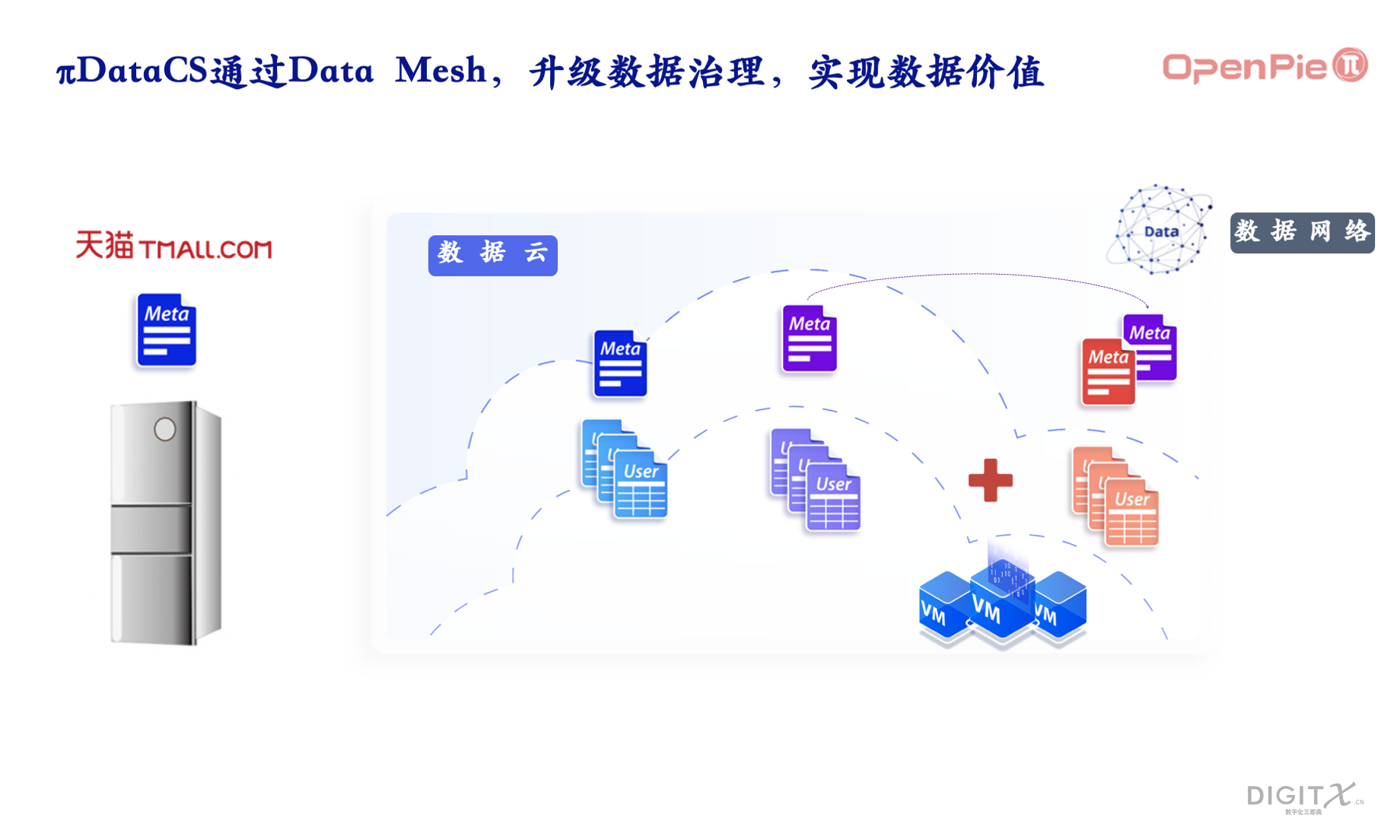
在拓数派的系统中,因为元数据独立且非常小,所有非常有利于所有者和经营者的互相访问和交流,直到数据经营者决定调用数据加工者的引擎的时候,才通过数据所有者的元数据授权访问数据所有者的用户数据。这个过程就好像冰箱厂家和冰箱消费者在天猫上的交易。双方其实交流的是冰箱的元数据,物理冰箱在仓库。直到双方决定交易的时候,冰箱才能从仓库发往消费者。
由于在云上,物理存储和物理CPU之间分离,使得访问的速度和性能不如PC,这是云上的唯一硬伤。拓数派团队针对这个难题,在海外部署了LTL实验室,秘密投入了2年的研发,通过FPGA新硬件,在FGPA中植入各种数据计算智能,使得CPU/GPU从云上的远程存储访问数据速度有机会远高于访问本地存储。正因如此,拓数派在1024宣布了行业领先的πFPGA产品。
拓数派核心团队以哥廷根合伙命名,继承计算的力量,在国内构造立足全球的大模型数据计算系统理论,并实现物理大模型数据计算系统。联合LTL实验室,构建云上最快的智能访问新硬件。在1024Foundation基金会,联合CMU等世界AI领先机构,以公益方式讨论未来模型的构建。拓数派(OpenPie)、LTL实验室(Leaf Tree Labs)和壹零贰肆数字产业基金会(1024Foundation)三驾马车,驱动数据计算只为新发现和AI向善。
“大模型数据计算系统——实现”的一个回复