
本文作者:周嘉宇(Jiayu Zhou)Computer Engineering,ECE Department,ZJU&UIUC。主要研究方向为LLM+Knowledge Graph Reasoning
项目介绍
作为AI4AI倡议初期启动的重要实践案例,该项目秉持“AI为人人”的理念,旨在探索一种普适而有效的AI课教模式。在带教老师的指导下,学员将通过问题导向的学习,全流程遍历项目框架,锻炼编程技能,增强信息检索与自学能力,了解并熟悉大模型的使用,在动手实践中探索全新领域。
前期推文中,我们已经介绍了RAG的主要技术栈。在此项目中,我们动手搭建了政策问答助手,并借此案例帮助学员建立对RAG流程更深入的了解。为结合学员背景,我们聚焦其切身关心的杭州市大学生创业创新政策条例。欲设计的智能问答助手旨在读取pdf政策文件,针对相关问题进行回答,且提供文本中的政策依据。全流程主要分为三部分:数据预处理、推理环节以及评价环节。这一过程中,学员实验了各种大模型和分段方法,最终尝试了用LoRA对模型的进一步优化。
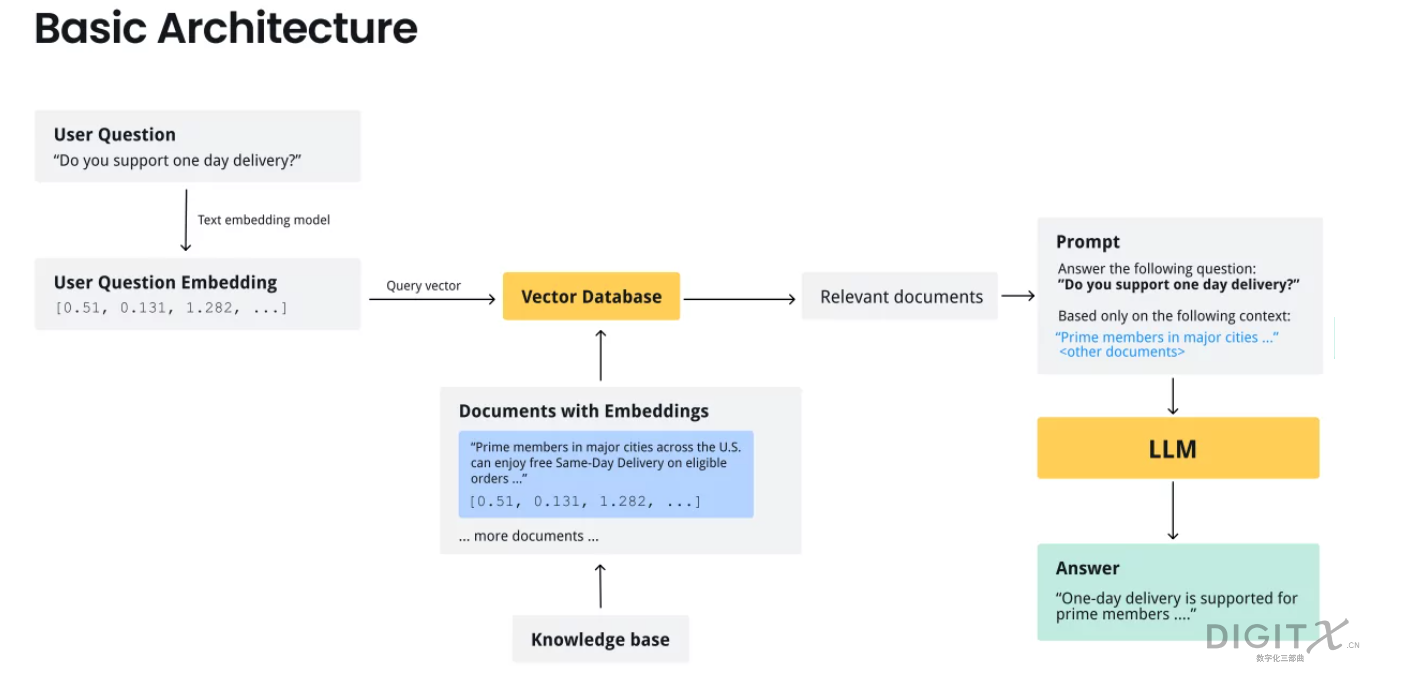
数据预处理
首先,我们将pdf政策文本转化成txt,这一步基于开源项目tesseract-ocr的简体中文版本实现。
def process_pages(pdf_path, start_page, end_page):
images = convert_from_path(pdf_path, dpi=300, first_page=start_page, last_page=end_page)
text_pages = {}
for i, image in enumerate(images, start=start_page):
gray_image = ImageOps.grayscale(image)
text = pytesseract.image_to_string(gray_image, lang='chi_sim+eng')
print(f"\nPage {i} Text:\n{text}") # Print recognized text
text_pages[i] = text + "\n"
return text_pages
在实施时,我们选取的政策文档为43页,经过jieba分词后,得到13194字,共471句话。
words = jieba.lcut(text)
num_words = len(words)
# Matches Chinese period, exclamation, question marks, and newlines
sentence_delimiters = r'[。!?]'
sentences = re.split(sentence_delimiters, text)
sentences = [s.strip() for s in sentences if s.strip()]
num_sentences = len(sentences)接下来是分段即chunking环节。我们调研了多种常用的分段方法,并着重实验了其中两种。
方法一:等字符分段法,也是最常见的分段方法。为适应大模型每次输入token的最大数量限制,并且考虑到单句平均28个字符,我们采用 width=300,overlapping=50 的分割法。
while start < total_words:
end = start + W
chunk_words = words[start:end]
chunk_text = ''.join(chunk_words) # Concatenate words without spaces
chunks.append(chunk_text)
start = end - overlap # Move the window forward with overlap
方法二:语义双重合并分段(semantic chunking double-pass merging)
其中First Pass的目的是准确识别主题的差异,将最明显的句子连接在一起。Second Pass进一步将以上小块组成主题各异的大块。对于主题的变化判定,我们设定了阈值 threshold = 0.7。
这里采用的sentence tokenizer是sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2,为句子生成84维的向量。
chunks = []
current_chunk = []
i = 0
while i < len(sentences):
sentence = sentences[i]
is_item = bool(item_pattern.match(sentence))
if is_item:
# Start a new chunk for the itemized list
if current_chunk:
chunks.append(current_chunk)
current_chunk = [sentence]
i += 1
# Add subsequent itemized entries to the current chunk
while i < len(sentences) and (bool(item_pattern.match(sentences[i])) or sentences[i].startswith(('(', '('))):
current_chunk.append(sentences[i])
i += 1
# Add the completed itemized list chunk
chunks.append(current_chunk)
current_chunk = []
else:
# Regular sentence processing with semantic similarity
if not current_chunk:
current_chunk = [sentence]
else:
# Compute similarity with the previous sentence
embedding_prev = get_sentence_embedding(current_chunk[-1])
embedding_curr = get_sentence_embedding(sentence)
sim = cosine_similarity(
embedding_prev.reshape(1, -1),
embedding_curr.reshape(1, -1)
)[0][0]
if sim >= 0.7: # Adjust the threshold as needed
current_chunk.append(sentence)
else:
chunks.append(current_chunk)
current_chunk = [sentence]
i += 1
# Add any remaining chunk
if current_chunk:
chunks.append(current_chunk)
在之后的实验中,我们发现使用同样的大模型,第二种语义分段法的预测效果要优于第一种等字符分段法。这可能是因为在方法二的初始分段过程中,我们注意到了句块过于零散的情况:

注意到,条例化的信息在这里被视为分段的标志,而相反他们正应被归为一类。于是我们确保“()”级别的itemization都能被正确合并。
item_pattern = re.compile(r'^(\(?[一二三四五六七八九十0-9]+\)?[.。、])') 以上两种分段法得到的结果,我们都以chunks.pkl和chunk_embeddings.pkl形式存储。
推理环节
在推理环节中,我们需要依据用户提问找到相关联的文本,设计提示词,随后调用大模型作答。
首先对query进行tokenization,找到相似度最高的top K段落(K=5):
def get_top_k_chunks(query_embedding, chunk_embeddings, K):
similarities = []
for idx, chunk_embedding in enumerate(chunk_embeddings):
sim = cosine_similarity(
query_embedding.reshape(1, -1),
chunk_embedding.reshape(1, -1)
)[0][0]
similarities.append((idx, sim))
similarities.sort(key=lambda x: x[1], reverse=True)
top_k = similarities[:K]
return top_k
为兼顾模型性能与潜在的参数优化可行性,我们选择Llama-2-7b-hf作为大模型。设计一组prompt后即可开始问答。
context = ''
for idx, sim in top_k_chunks:
chunk_text = ''.join(chunks[idx]) if isinstance(chunks[idx], list) else chunks[idx]
context += f"【内容{idx+1}】\n{chunk_text}\n\n"
prompt = f"""你是一名智能助理,请根据以下提供的政策内容,回答用户的问题。请确保回答准确且基于提供的内容。如果无法找到答案,请告知用户。
{context}
用户提问:
{query}
你的回答:
"""
terminal>>
请输入您的问题:杭州市海外高层次人才创新创业有哪些补助?
生成的回答:
参照中国杭州大学生创业大赛在杭落地项目资助条目可见该回答虽言之成理,仍存在改进空间。问题在于,如何量化评价这一模型的回答准确度?为此,我们引入了多项选择题(MCQ)作为评价集。
评价环节
由于大模型的输出是自然语言且充满不确定性,我们很难量化某一回答的准确度。因此,有必要建立具备准确答案的评价集。我们希望评价集具备如下特征。第一,含有一个准确答案,而且其他三个答案虽错误,在常识范围仍有一定可信度,如此才能体现作出判断的不是凭借大模型的前置知识,而是基于retrieved document。第二,正确答案在ABCD中随机分布,防止未来在训练过程过拟合。借助人工标注和AI辅助,我们构造了30组评价问答题,示例如下:
{
"query": "哪些企业能获得杭州市的创业补助?",
"options": {
"A": "所有注册在杭的企业均可申请。",
"B": "符合政府补助要求的创新型企业。",
"C": "补助只提供给年收入超过一定标准的企业。",
"D": "只限于科技创新型企业。"
},
"ground_truth": "B"
},
在这组评价集上,我们分别验证了两种分段法。鉴于生成的回答不总是如指令里声明的那样,仅仅给出ABCD中的选项,我们提取回答中首个出现的合法大写字母作为predicted answer。
for char in predicted_answer:
if char in ['A', 'B', 'C', 'D']:
return char
return None
经多组实验,等字符分段法取得了13.3%-20%的准确率,而语义分段法取得了26.7%-50%的准确率。总体而言,语义分段法所产生的文本在该评价集上更加可靠,除了上述提及的合并itemization的原因,还可能是因为等字符分段法恒定的top K chunks输入宽度过大,导致大模型更难准确理解指示。此处展示正确和错误的预测案例各一组以供参考:


至此为止,我们可以对不同大模型与分段法在该评价集上的性能搭配进行总结。
| V1=equal chunking | V2=semantic double merge chunking | |
|---|---|---|
| Open_llama_7b | 16.67% | 4.17% |
| microsoft/phi-2 | 33.33% | 8.33% |
| Llama-2-7b-hf | 20% | 50% |
注:显示的准确率为多组实验取得的最高值。当调用更小模型时,我们相应更改了分段的策略。例如对于microsoft/phi-2,我们选取W=80,overlap=40。对于Open_llama_7b,我们选取top K=3。
LoRA on RAG:从训推一体到深度学习
在之前的流程中,学员搭建了标准的RAG流程,经历了种种调研和debug,可谓已从初窥门径成长到能独当一面处理复杂任务了。那么这套项目方案有何进一步改进之处呢?我们不难发现,模型的训练和推理并没有分离。这导致了所有的hyperparameters都是认为设计而缺少迭代优化的过程,这也是前机器学习时代的常见现象。随着深度学习发展至今,已有多种方法调参,而其中能以较低成本实现大模型局部微调的,当属LoRA最受欢迎。
什么是LoRA?
LoRA(low-rank adaptation)是一种快速将机器学习模型适应新环境的微调技术,不同于RAG使模型聚焦于某类数据,LoRA有助于模型更倾向于某种特定任务。面对层出不穷的细分任务,微调整个大模型通常是成本过高的,而LoRA提供了一种快速调整的方法。它在生成QKV的模型部分加上低秩矩阵 ,其中r远小于m和n,使得只需训练A和B这两个残差(residual)。因此,LoRA影响的其实是自注意力层和交叉注意力层。
把LoRA应用到RAG Chatbot
开始前,先将先前的评价集dataset.json以 20:5:5 拆成 train:valid:test。设置lora_config的参数。
def fine_tune_lora(model_name, train_dataset, valid_dataset):
# Load the pre-trained LLaMA model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# Apply LoRA to the model
lora_config = LoraConfig(
r=8, # Low-rank approximation factor
lora_alpha=16, # Scaling factor for the LoRA weights
target_modules=["q_proj", "k_proj", "v_proj"], # Target the attention layers
lora_dropout=0.1 # Dropout rate for LoRA layers
)
model = get_peft_model(model, lora_config)
把evaluation_metric设置为accuracy。定义可训练的参数,以及训练器。为节约GPU资源,可下调精度。
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
fp16=True, # Enable mixed precision
evaluation_strategy="epoch",
save_strategy="epoch",
logging_dir='./logs',
logging_steps=10,
save_total_limit=2,
load_best_model_at_end=True,
dataloader_num_workers=4,
push_to_hub=False,
metric_for_best_model="accuracy",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
def compute_metrics(p):
logits, labels = p
predictions = torch.argmax(logits, dim=-1)
loss = torch.nn.CrossEntropyLoss()(logits.view(-1, logits.size(-1)), labels.view(-1))
return {
'eval_loss': loss.item(),
'accuracy': accuracy_score(labels.view(-1).cpu().numpy(), predictions.view(-1).cpu().numpy())
}
# Train the model
trainer.train()
# Save the fine-tuned LoRA model
model.save_pretrained('fine_tuned_lora_llama')
tokenizer.save_pretrained('fine_tuned_lora_llama')
最后预计需要64.00MiB GPU空间。技术原理已经阐明,限于算力资源,工程部分留作将来的拓展实践。
教学计划
我们根据学员的背景,由易到难制定了一系列Project Milestones。
Project Milestone 1:将给定的pdf政策文件转化成txt;列出outline;设计10道选择问答题。
Project Milestone 2:把txt分成N个W长度字符的chunk。
Project Milestone 3:用现有库将给定文本tokenize。
Project Milestone 4*:以query作为输入,计算每个chunk的embedding similarity;排序;设计一个方案(threshold或accumulated proportion),选出relevant chunks。
Project Milestone 5*:调用大模型如Llama-2-7b-hf,用query+relevant chunks组成开放式问答input,encode+decode生成回答。得到初步结果。
Project Milestone 6*:用选择题集的query进行评估,用不同方案重复测试
Project Milestone 7:总结归纳与改进。
注:每个PM默认一周时间。带*表示较难,可延长至两周。
数据处理IDE为VSCode;
测试环境及工具为AI-Studio,PieCloudDB;
训练环境为NVIDIA A100-SXM4-80GB,Driver Version: 535.183.06,CUDA Version: 12.2
学员反馈
Kris:“在项目期间,我试着通过python将图片文件转化为文本,并且协助测试初步训练的模型的准确性。通过此项目,我锻炼了解决问题的能力并且提升了自己的编程技巧。我很高兴参与AI4AI,同样感谢老师和伙伴的帮助与支持。”
致谢
感谢冯雷先生(Ray Feng)发起AI4AI倡议,为我们实践AI公益教育搭建了平台。感谢黄奕铖先生(Marco Huang)对我们的教学项目提供技术原型与流程指导,也感谢OpenPie的各位同仁和前辈给予的关心和支持。
参考资料
1, https://github.com/flyyuan/pdf2txt-chinese
2, https://bitpeak.com/chunking-methods-in-rag-methods-comparison/