LLMs (Large Language Models ) 正在引领人工智能技术的新浪潮。LLMs 的强大功能已引起了众多头部企业以及科技爱好者的浓厚兴趣,他们竞相采用这些由人工智能驱动的创新解决方案,旨在提高运营效率、减轻工作负担、降低成本支出,并最终激发出更多创造业务价值的创新想法。然而,要真正发挥 LLMs 的潜力,关键在于“定制化”。即企业如何将通用的预训练模型,通过特定的优化策略,转化为契合自身独特业务需求和用例场景的专属模型。鉴于不同企业和应用场景的差异,选择合适的LLM集成方法便显得尤为重要。因此,准确评估具体的用例需求,并理解不同集成选项之间细微的差异和权衡,将有助于企业做出明智的决策。
本文使用huggingface PEFT库的QLoRA微调方法,实现了对chatGLM2-6B 大模型在特定数据集上的微调。
环境配置
CPU : Intel(R) Core(TM) i7-6950X CPU @ 3.00GHz
Memory: 64GB
GPU: GeForce RTX 2080 Ti , 4352 cores , 11GB
Ubuntu20.04 server, CUDA 12.1
chatGLM2-6B 介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型.ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
QLoRA 介绍
大模型时代, 模型参数动辄10B起, 训练的代价非常高昂,即使是微调也对计算资源有很高要求。 那么如何使用较少硬件资源进行高效的finetune方式就非常必要了。LoRA就是高效微调方法的一种, 减少微调显存占用的同时,保持微调的性能和准确率。
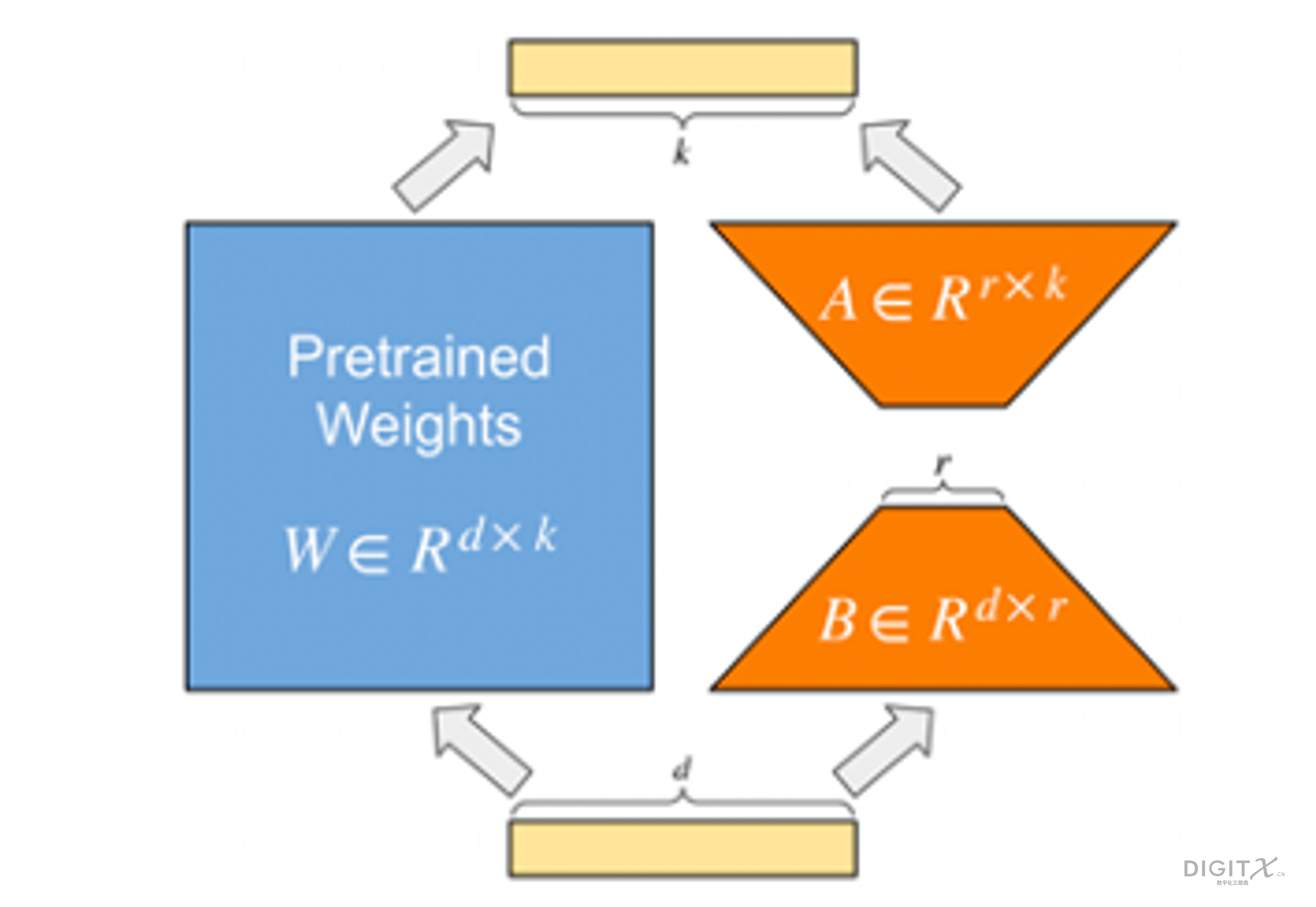
论文中作者的实验也证明了这一点。 在GPT-3 175B的finetune中, 采用LoRA微调显存的消耗从1.2TB 降低到了350GB, 大约是三分之一.
目前大多数LLM都是基于Transformer架构,其中包含一些全链接层. 在全链接层中存在参数矩阵,通过将输入embedding与参数矩阵相乘,我们得到全链接层的输出矩阵。 在预训练的LLM中,存在许多具有很大维度的参数矩阵,即使微调这些参数也会消耗大量的硬件资源。 针对这些参数矩阵,如上图的W, LoRA的方法是增加一个旁路结构,旁路是A和B两个矩阵相乘。 B矩阵的维度是d x r, A矩阵的维度是r x k, 其中d,k 远大于 r , 一般r取1,2,4,8。 那么这个旁路的参数量将远远小于原来网络的参数W。LoRA训练时, 我们冻结原来网络的参数W, 只训练旁路参数A和B。 由于A和B的参数量远远小于W, 那么训练时需要的显存开销就大约等于推理时的开销。
QLoRA (Quantized LoRA) 基于LoRA, QLoRA 引入了多项创新技术,在不牺牲性能的情况下节省内存:(a) 4 位 NormalFloat (NF4),一种新的数据类型,理论上对于正态分布权重来说是最佳信息 (b) 双量化,通过量化来减少平均内存占用 量化常数,以及 (c) 用于管理内存峰值的分页优化器。
DataSet介绍
关于数据集, 我们使用根据拓数派(OpenPie)内部知识库创建的训练数据集,具体形式如下图所示。 每条训练数据有两个字段,instruction 字段包含了一组关键词, output字段包含了一段关于关键词的描述信息。推理阶段模型会根据输入的关键词输出一段相关的描述。
训练数据集包含约4w条训练数据(包含大量重复数据),验证数据集包含1k条验证数据。

微调过程
我们使用huggingface PEFT库中的QLoRA实现进行微调, 核心脚本如下
import os
import argparse
from typing import List, Dict, Optional
import torch
from loguru import logger
from datasets import load_dataset
from transformers import (
AutoModel,
AutoTokenizer,
HfArgumentParser,
set_seed,
TrainingArguments,
Trainer,
BitsAndBytesConfig
)
from peft import (
TaskType,
LoraConfig,
get_peft_model,
set_peft_model_state_dict,
prepare_model_for_kbit_training
)
from peft.utils import TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING
tokenizer = AutoTokenizer.from_pretrained(global_args.model_name_or_path, trust_remote_code=True)
q_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=_compute_dtype_map[global_args.compute_dtype])
model = AutoModel.from_pretrained(global_args.model_name_or_path,
quantization_config=q_config,
device_map='auto',
trust_remote_code=True)
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
target_modules = TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING['chatglm']
lora_config = LoraConfig(
r=global_args.lora_rank,
lora_alpha=global_args.lora_alpha,
target_modules=target_modules,
lora_dropout=global_args.lora_dropout,
bias='none',
inference_mode=False,
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
train_dataset = get_datset(global_args.train_data_path, tokenizer, global_args)
data_collator = DataCollatorForChatGLM(pad_token_id=tokenizer.pad_token_id, max_length=model_max_length)
# train
trainer = LoRATrainer(
model=model,
args=hf_train_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator
)
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
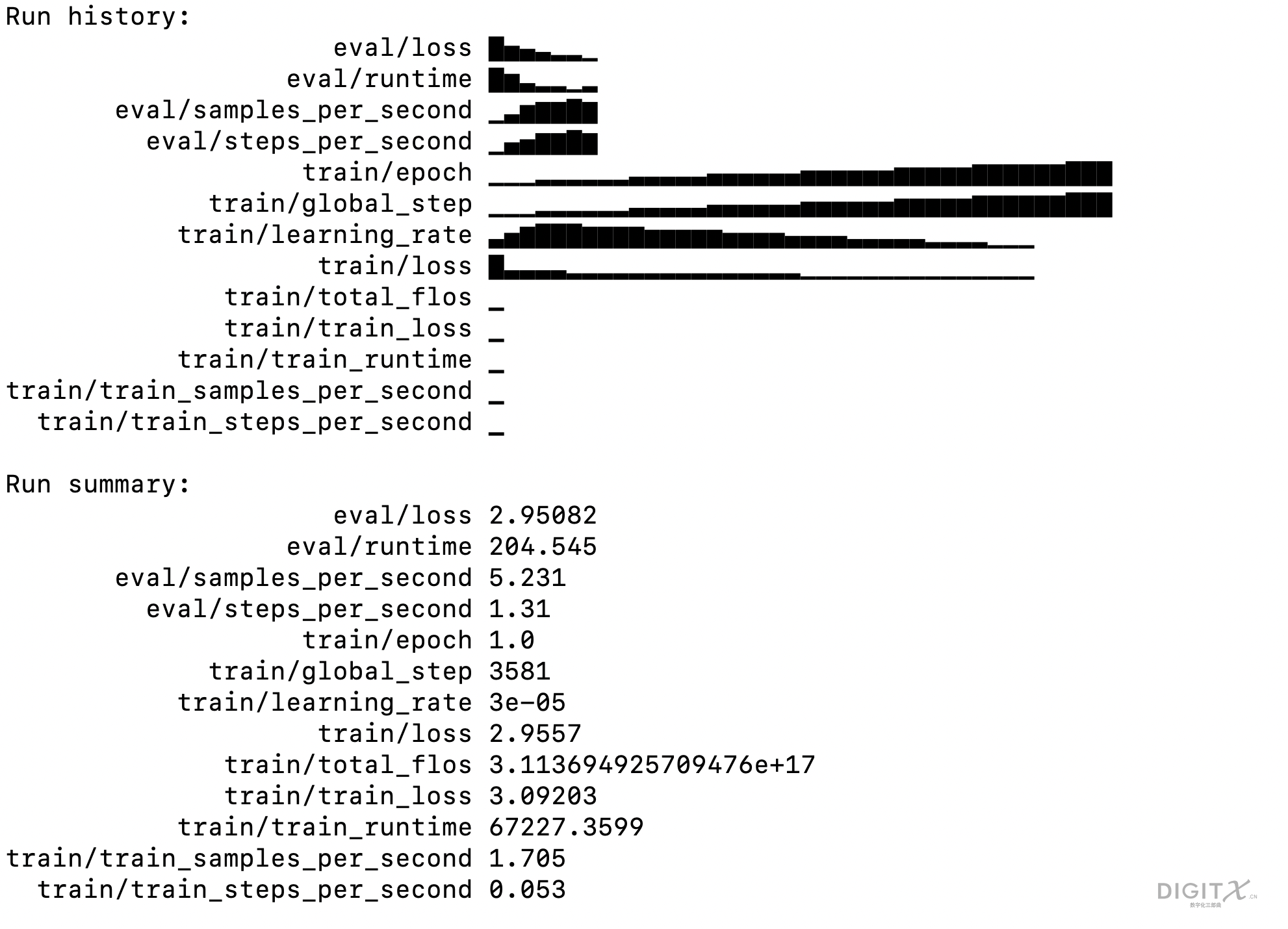
trainer.model.save_pretrained(hf_train_args.output_dir)微调过程的资源消耗和结果如下图所示
推理过程
推理使用的脚本如下, 对于给定的输入关键词, 分别输出模型微调前和微调后的结果。
import torch
from transformers import AutoModel, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel, PeftConfig
peft_model_path = 'saved_files/chatGLM2_6B_QLoRA_t32'
config = PeftConfig.from_pretrained(peft_model_path)
q_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float32)
base_model = AutoModel.from_pretrained(config.base_model_name_or_path,
quantization_config=q_config,
trust_remote_code=True,
device_map='auto')
input_text = '拓数派#openpie#数据库#开发团队#宗旨'
print(f'输入:\n{input_text}')
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path, trust_remote_code=True)
response, history = base_model.chat(tokenizer=tokenizer, query=input_text)
print(f'微调前 ==> :\n{response}')
model = PeftModel.from_pretrained(base_model, peft_model_path)
response, history = model.chat(tokenizer=tokenizer, query=input_text)
print(f'微调后 ==>: \n{response}')
微调结果如上图所示, 可以看到微调前chatGLM2对拓数派的了解有限,输出的结果基本是错误的,或者是一些较为通用的描述语言。 在特定的数据集上进行微调后, chatGLM2可以比较准确的回答有关拓数派的问题了。
综上可以看出,通过在特定数据集上对大语言模型进行微调,可以完成对模型在特定领域的“定制化”,使得模型可以更加契合企业自身独特业务需求和用例场景。
参考链接
https://arxiv.org/pdf/2106.09685