拓数派在πDay上宣布全面完成数仓云原生虚拟化。在最新发布的“PieCloudDB Database Management System 2.x”系列版本 (以下简称PieCloudDB2)全面完成多个云原生虚拟数仓并发执行,各个动态虚拟数仓根据自己的授权访问S3上加密并统一的用户数据库实例数据。 云原生数仓虚拟化使得用户可以将多个数仓整合,数量级地减少计算资源成本的时候,数量级地提升数据计算空间。
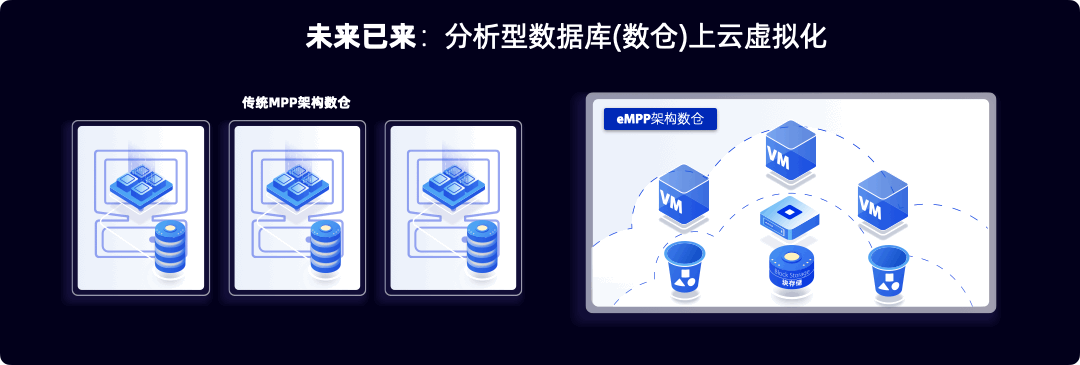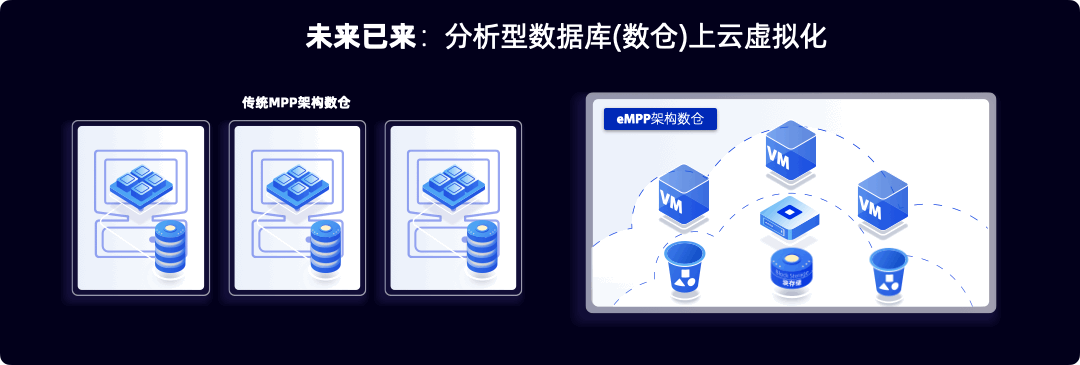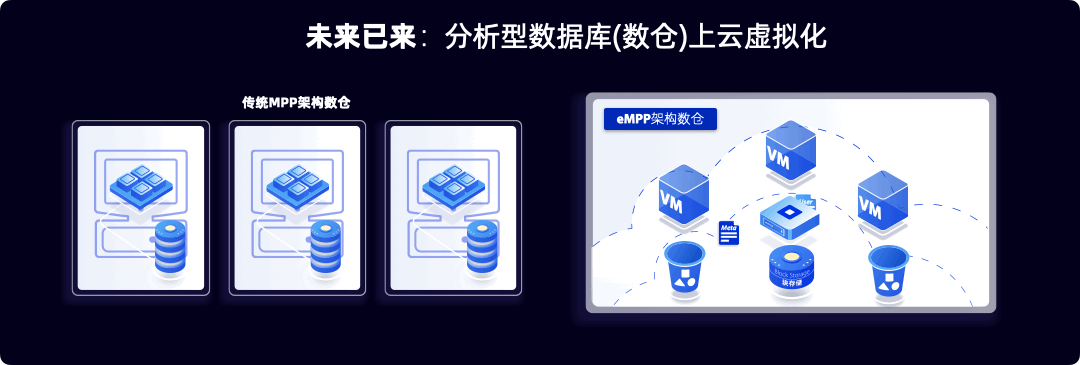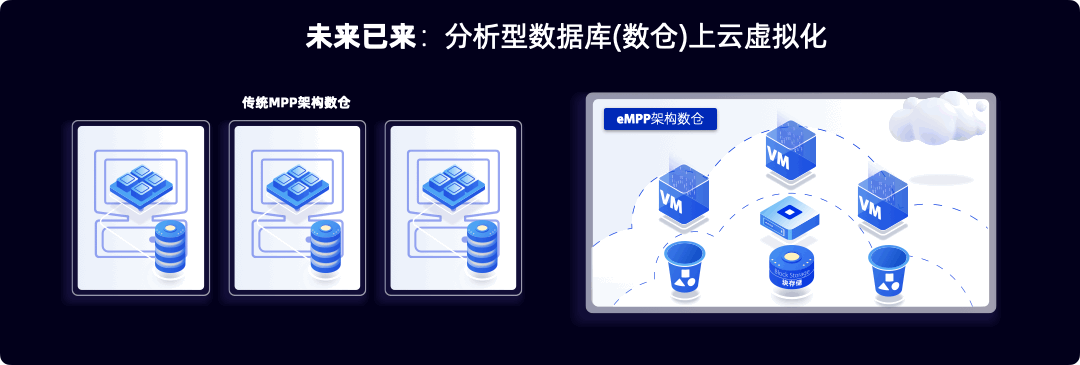
大部分数据库管理系统都产生于2005年前,而云计算的启动在2006年。云计算广泛铺开是在2015年,亚马逊在第一季度财报第一次对外公布AWS云业务财务数据。云计算的虚拟化集群架构颠覆了PC集群架构。如图1所示,左边是典型的PC集群,有一台台服务器组成,它们的特点是有本地硬盘存储。这使得所有的服务器都是有状态的,很难替换和升级,也很难在运行期扩展。
而虚拟化技术的兴起是云计算的核心技术突破点,在云上,服务器都是以虚拟机(或者到最近的容器)的形式呈现,虚拟机运行在没有本地硬盘的服务器(Diskless Server),虚拟机使用的是云上的块存储(Block Storage)和对象存储(Object Storage)。云上的这种存储和计算分离的虚拟机集群带来云上弹性的能力以及软硬分离的高容错和高在线能力,但是大部分PC时代的数据库安装在云上的时候,还是假装存储在本地,忽略云上带来的弹性机会的同时,也没有对挂载上来的不在本地的存储做任何性能的优化。带来的结果是上云后不仅慢了而且贵了,也没有享受到云的任何红利。行业内一般把这种上云的数据库叫做云洗澡(Cloud-washed)数据库,读者可以理解为阳澄湖洗澡蟹,不在阳澄湖的蟹洗个澡并没有享受到阳澄湖的优质水,反而劳民伤财。
2015年前后,数据库行业的少数几只研发力量意识云原生数据库的必要性,当时作者团队在云原生第一股Pivotal公司,我们已经深刻认识到我们的MPP数据库(以下可能和数仓混用)需要推倒级重写,实现云原生。Pivotal团队提出云原生的含义是第一天诞生在云里。我们也意识到,检查一个MPP数据是否是云原生的标准是数据库是否有虚拟化能力,也就是利用的无本地盘虚拟化服务器可以动态创建多个虚拟数仓。
以下我们用101课程的语言来解释一下这个推倒级重写的核心思想。 一个MPP数据库的核心构成是用户数据,元数据(也叫Catalog)和计算引擎。在PC机时代,我把三部分都放在一台服务器上,元数据和用户数据都放在本地硬盘,而计算在交给在本地CPU上运行的操作系统。通过服务器组群来实现分布式能力。市场主流的MPP数据库,例如Teradata和Greenplum都是这种结构。
而在云算时代,我们把这三个逻辑组件映射到云上新的物理架构。元数据通常是数据库系统自身的核心数据,它通常不会太大量,但是性能非常重要,所以我们把它放在高性能但略微昂贵的块存储(Block Storage里面)。考虑到用户数据的海量,通常在几个TB到几个PB,而云上的对象存储更加便宜,所以我们需要把用户数据放在对象桶。最经典的对象存储服务就是亚马逊提出的S3(Simple Storage Service的3个首字母S)。我们把计算交给云上的虚拟服务器或者最近兴起的容器上的操作系统。
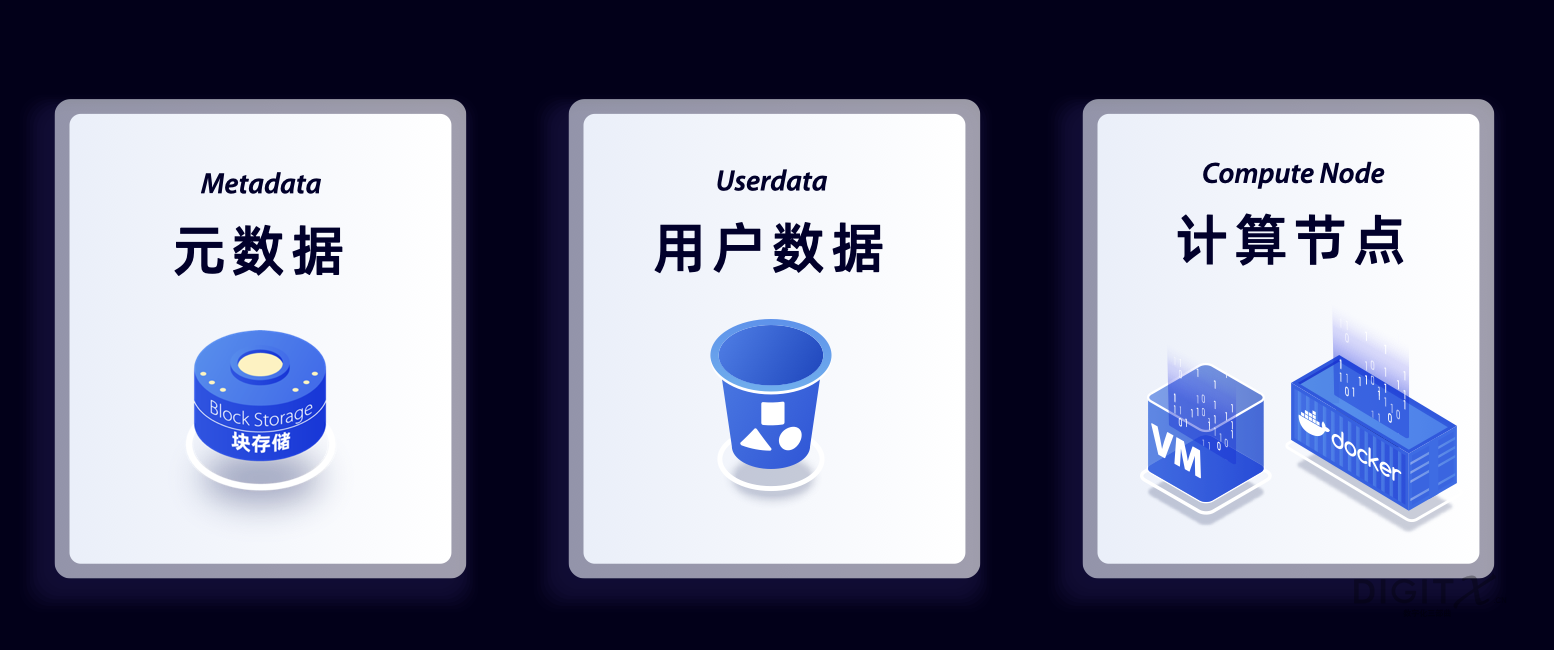
这个一个数据库核心组件的拆解并在云上重组,又要保证数据库的标准SQL集合和数据库的ACID事务属性,重写的难度是非常高的。传统的数据库又受限于自己的眼前业务流水,摆脱不了云洗澡的惯性。这样一种创新,属于典型的破坏式创新(Disruptive Innovation)。根据《创新者的窘境》(The Innovator’s Dilemma),建议成立一个新型的机构完成这样的破坏式创新。在2015年前后,世界上有三支力量在这个创新路径上发力:亚马逊通过收购ParAccel开始在AWS云上改造存算分离的Redshift;Oracle的Benoit Dageville和Thierry Cruanes在美国知名风投机构Sutter Hills支持下创立Snowflake开始云原生数据库的研发;拓数派这支队伍,深浸在虚拟化的提出者VMware和云原生的提出者Pivotal里面,主导着近10年的Greenplum开源研发,在2021年在国内顶级产业基金和PE基金支持下,利用云原生架构,全面朝MPP数据库虚拟化前进。(更多拓数派起源故事参考《Day-1准独角兽「拓数派」的起源》)

这三支队伍都按图3结构打造云原生数据库,但是侧重点各有不同。Redshift主要看中亚马逊一方云的存算分离;Snowflake看中作为第三方云的跨云的存算分离;拓数派立身于中国,更看中云原生数仓虚拟化技术突破带来的计算红利,可以普及到私有云、公有云和行业云。 Redshift和Snowflake都不关心私有云,所以也不关心数仓虚拟化给私有云带来的数仓整合的红利。
拓数派在2022年的10/24发布了存算分离的云原生数据库,引起了业内很大的关注,也获得了各个行业头部企业的深度合作。在πDay,我们又完成了多个虚拟数仓并行动态创建和关闭,每个数仓动态扩容和缩容。数仓虚拟化技术带来的数仓整合,就好像服务器虚拟化带来的服务器整合一样的效果。传统企业的数仓按照如下视频5所示进行整合。在整个整合的过程当中,企业已经可以将硬件成本下调到50%以下,真实有数量级下调的机会。整合后,每个虚拟数仓根据自己的数据授权,反而可以在组织全域数据空间进行计算。
数仓一旦上云和虚拟化,它就获得了云上新架构提供的无穷多的技术红利。以下简单列举其中可以推导出来的商业价值:
- 永远避免PC数仓带来数据孤岛和碎片化:因为PC数仓没有办法像云原生数仓可以在共享数据和计算资源的同时动态创建虚拟数仓。在一个机构有新应用的时候,很多时候会创建新的数仓,这就会导致各个数仓直接数据孤岛。各个数仓为实现互访,很多时候不得不copy数据,导致多副本。多副本不仅存储成本增加,更会导致数据维护成本高昂和数据不同步质量下降。
- 每个虚拟数仓可以根据云上计算资源进行动态调配:任何一个虚拟数仓在没有workload的时候,计算资源可以释放,不仅减少了费用,也可以将计算资源调配给其它需要计算资源的虚拟数仓
- 用户数据存储按需付费:对象存储是按需付费,而申请块存储/本地磁盘存储,空余的空间其实是收费的。 我们期望云原生中,数据和计算都是按需弹性付费。
- 获得计算资源换时间的能力:任何一个虚拟数仓,可以动态申请更多的计算资源,在同样的时间内进行更深度的计算。这就意味着所有的数仓应用,只要能用好云上有更多的计算资源,都能获得更好的结果
- 高安全性:整个PieCloudDB的数据在落地存储介质前都已经是加密的,所以用户数据永远不会泄露。
- 高可靠性:PieCloudDB的用户数据存储在S3,甚至PieCloudDB的元数据都在S3有备份。S3自己带有多备份容错,除非自然灾害不会丢数。为了抵抗自然灾害,PieCloudDB因为计算和存储分离,用户也很容易对自己的S3数据进行跨区域的灾备,也可以对私有云和公有云,私有云和私有云,公有云不同厂商直接进行灾备。
- 高在线能力:因为虚拟数仓调用虚拟服务器或者容器的过程对于用户是无感知的(Serverless),所以任何硬件故障,虚拟机或者容器故障,PieCloudDB会自动重新分配,用户一劳永逸地从运营和故障中释放出来,专注在自己的业务。
另外,我们的优化器”达奇”对于S3的存储环境全面优化.我们定义的全新存储”简墨”,不仅支持了数据库文件格式,也为未来其他的数据格式和其上的数据库以外的执行引擎做了铺垫。
总结来说,PieCloudDB这项元原生数仓虚拟化创新,带来了数据计算行业的柏累托改进。我们对照服务器虚拟化技术来总结一下数仓虚拟化带来好处:
| 服务器虚拟化 | 数仓虚拟化 |
| 云计算时代的到来 | 数据计算时代到来 |
| 服务器整合,降低服务器硬件成本 | 数仓整合,降低服务器硬件或者虚拟机成本 |
| 云计算平台统一运维降低成本 | 数据计算平台统一 运维降低成本 |
| 服务器资源池可用空间增大 | 数据资源池可用空间增大 |
| 虚拟机高在线 | 虚拟数仓数仓高在线 |
| 虚拟机动态迁移对硬件无感知 | 虚拟数仓动态spinoff/retire对计算资源无感知 |
就好像欧几里得几何因为第五公理变换到黎曼几何,打开了广义相对论新的空间。PieCloudDB因为从PC公理到云原生公理的变化,创造了数仓虚拟化技术,打开了数据计算的新空间。更多的新空间的红利,有待读者和拓数派一起探讨和证明!
科技创新引领商业变革,棒!