

Day-1准独角兽拓数派于2022年4月下旬再获元禾投资和东吴证券投资。在此前,腾讯于2021年7月和12月连续完成了两次投资。短短9个月内,这个Day-1准独角兽连续完成三次增资,并快速进入成长稳定期。拓数派这9个月的成长过程,行业平均需要5年甚至更久的时间。在这次投资完成后,不少投资界和科创界的朋友希望我分享一下拓数派的理念,所以我撰写了这篇博文以供参考。
在云原生和数据库的创投界的朋友们知道,我与团队在中国掌舵的上一个项目是Pivotal中国(和其下的旗舰数据库产品Greenplum)。2013年,Pivotal和拓数派一样,有着类似的含银汤匙的出生。不过Pivotal虽然是Day-1独角兽,但是届时的母公司EMC和兄弟公司VMware一起控制了80%以上(这也是为Pivotal后续的收购故事埋下了伏笔)。Pivotal的梦想是打造云原生操作系统,成为容器云和数字化转型的先驱。Pivotal用了不到5年的时间递交了S-1表(美国SEC的上市申请表),被誉为 [PaaS云第一股](参考我的 [blog])。2020年初,因为各种复杂的原因,Pivotal整体出售给了VMware。(而今年的这个时候,博通又宣布了整体收购VMware。)从2020年到2021年,伴随Pivotal中国团队整体成功整合进入VMware中国,我很欣慰Pivotal的云原生操作系统和帮助所有企业成为软件公司的使命告一段落。与此同时,我开始思考数字未来这个无限游戏的下一个使命。
大约10年前,我告别了位于美国硅谷Redwood Shores的Oracle生活,接受了Greenplum中国和后续Pivotal中国的使命。原因除了因为Greenplum创始人和Pivotal董事长在业内的影响力之外,很大一部分是因为Greenplum的大数据使命和Pivotal的云原生使命处于一个令人兴奋的数字未来的十字路口。在我眼里,数字化的核心也是数学化。我的中学时光,沉浸在物理学科把自然界数学化所带来的美妙之中,参加奥赛的时候也阅读了大量古典力学。牛顿力学的伟大之处不仅仅因为三定律和万有引力定律,更在于牛顿用数学建模自然科学(论文的原题目是《自然哲学的数学原理》)这一数学化,直接带来了工业革命。到了近代,来自哥廷根大学的希尔伯特提出形式化数学后,为机械化数学和逻辑奠定了基础,导致了图灵构造了虚构的理论上的计算机和冯诺依曼(曾是希尔伯特的助理)等人构造了程序存储的计算机,从而奠定了数字化基础。如果说古典物理时代模型方法主要建立自然科学规律的数学定理,那么,近代我们数学化人类社会和智能主要采用计算模型的方法来仿真人类社会和个体智能。这个时代的数学化也同时引入了数字化(参考《数学化和数字化》)。CMU作为人工智能两大诞生地之一,把数字输入看作符号,用计算模型看作智能仿真大脑操作符号的过程,奠基了符号学派人工智能的第一个AI程序“逻辑学家”。随着计算技术的几何级指数的发展,我们有机会把符号系统升级到数据系统,用数据来训练程序,让程序自己给自己编程。我们团队把这样一种探索社会和个人智能的方法,定义为数据计算方法。所以我们将这个公司的使命定为“数据计算、只为新发现(Data Computing for New Discoveries)”。我出任CMU上海校友会主席的驱动力,也是希望携手CMU中国社区一起,把符号学派推进到数据计算时代。
用少量符号和计算模型来建模人类社会和个体智能,奠定了早期的AI,取得了巨大的成绩。但是更多的红利却依赖于更多的数据量和更高计算能力。一般说来,任何一个模型,只要处理得当,使用更多的数据和计算,就能产生更好的预测准确率。这个不难理解,高中物理课本讲到的自由落体的测量,通过测量更多的点来获得大量的实验数据,这样才能算出更精准的下落加速度g。如下图所示的自然语言模型中,更多的数据计算的情况下,各个模型都得出了更好的准确率。
(参考:Banko, M., & Brill, E. (n.d.). Scaling to Very Very Large Corpora for Natural Language Disambiguation. Aclanthology. https://aclanthology.org/P01-1005.pdf)
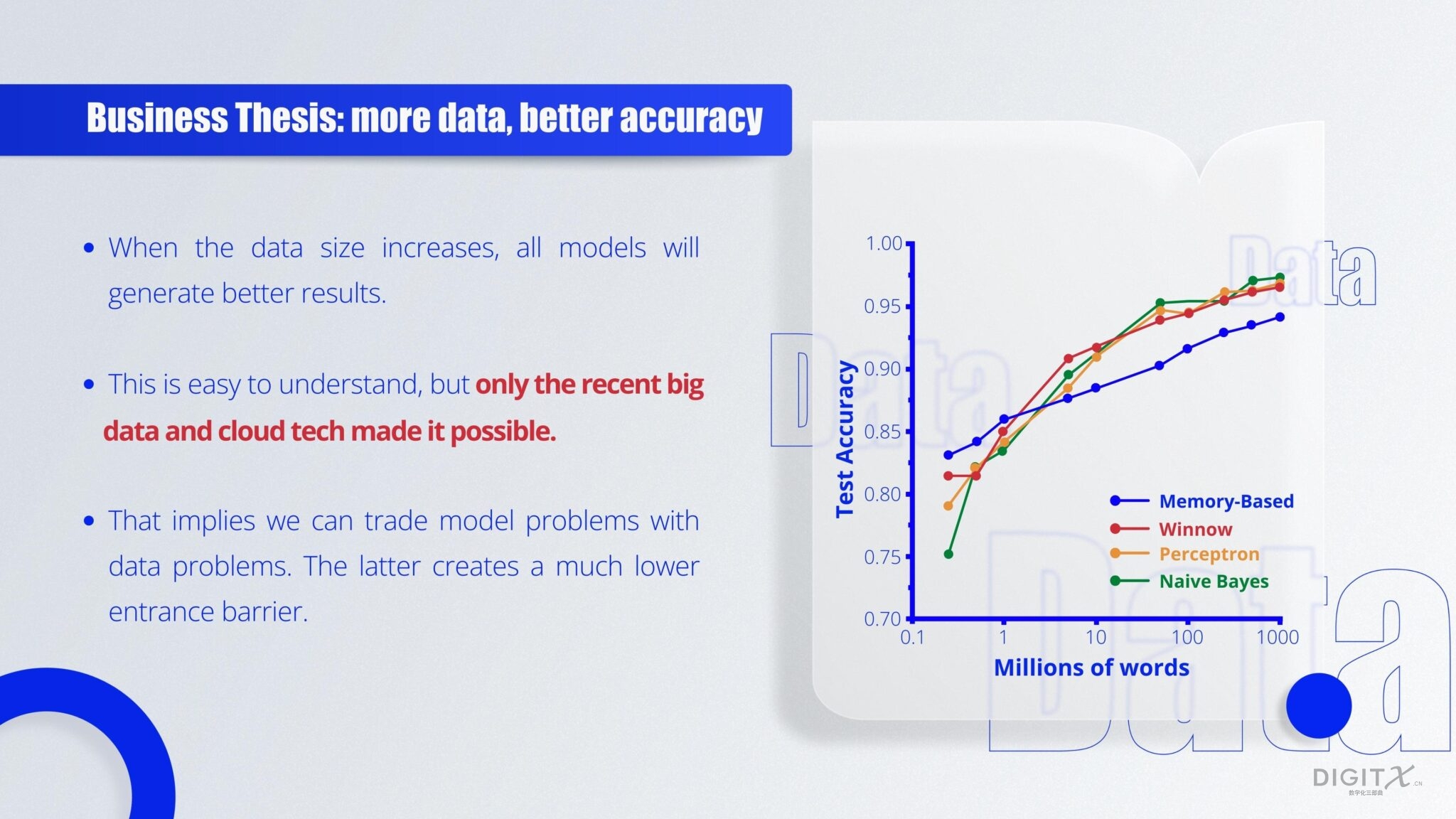
这样一个简单却有效的洞察把人类社会带入了大数据时代。首先,我们不再随便删除数据,而是希望把数据存储起来用于分析。其次,当我们不能构造类似神经网络等开天辟地的新模型的时候,我们可以寻找更多的数据集、运用更强大算力来提高模型的准确率,以数据计算能力来换模型能力。(这不是说模型能力不重要,而是说它的门槛太高,后面我们会就模型能力继续探讨)。既然数据计算,能够让我们找到新发现,那么我们就应该不遗余力地去驱动数据计算平台的创新。我们的第一款产品πCloudDB就是建立在这样的一个底层基础计算技术的探索上面。如下图所示,我们认为计算技术目前经历了三代平台: 1)大型机时代;2)PC机时代;和3)云计算时代。每一代计算平台的变更,都带来了数据计算技术的突破性创新的可能性。
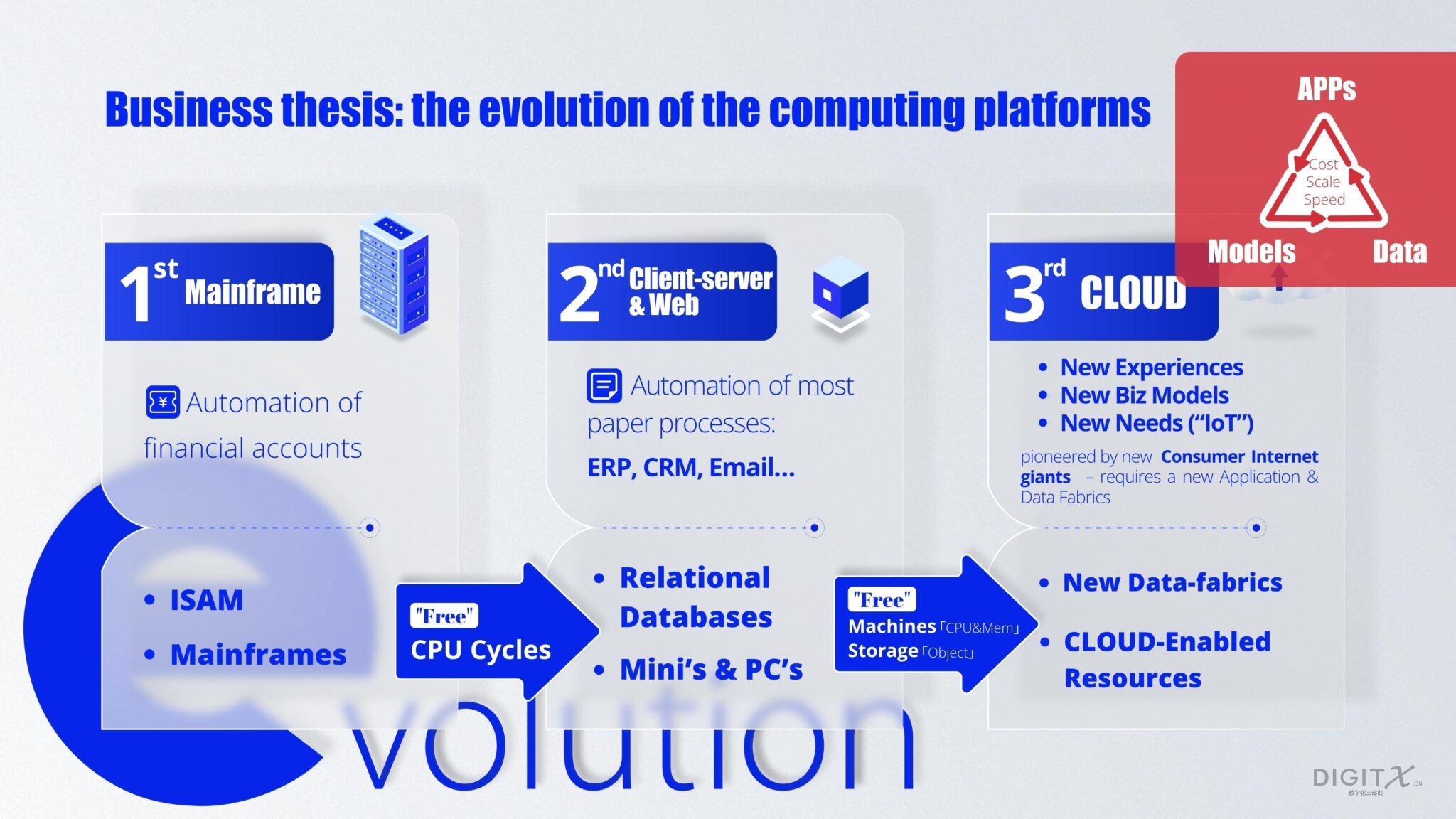
在大型机年代,计算资源极度稀缺,我们的主要思维方式是“除非万不得已,尽量用人工(而不是计算)”。在PC机时代,因为摩尔定律,计算资源开始丰富,PC机通过组群可以取代大型机,而极大地降低在大型机年代,计算资源极度稀缺,我们的主要思维方式是“除非万不得已,尽量用人工(而不是计算)”。在PC机时代,因为摩尔定律,计算资源开始丰富,PC机通过组群可以取代大型机,而极大地降低了计算的门槛。Oracle,TeraData和Greenplum等产品就诞生在这一时期。Greenplum作为一个分析型数据库,整理和存储了大量结构化数据,帮助数据计算在各行各业产生智能:银行通过风控计算降低贷款坏账率,零售行业通过计算提高用户的复购率,医药公司通过计算可以提升新药的有效性。随着云计算机时代的到来,不仅使得计算成本极大地降低,也提供了无限丰富的计算资源,释放出数据计算产生智能的更多机会。Pivotal公司也是因为这个时代大流而创建,Pivotal的云原生操作系统的主要目标是让传统500强企业可以像互联网公司一样快速创建数字应用。但是在我看来,云原生更重要的意义,是为数据计算产生智能带来前所未有的机会。
第一阶段产品πCloudDB的初衷和理念
拓数派认为数据计算以PC机为单位的切割方法是数字未来的最大掣肘。如果说云上有无限伸展的计算资源和存储资源,并且这两个资源的伸展意味着数据计算能产生更好的结果,那么我们应该突破PC时代计算平台的限制,大胆地想象在云上计算平台的新可能。因此,拓数派决心重新定义云时代的数据计算平台,以更好地去落地自己的理念。另外,在数据计算中,结构化数据带来的计算结果比非结构化数据更加立竿见影。为此,拓数派的第一步,利用云计算的计算技术的变革,重新打造“出生于云”的(外面一般叫云原生)、以分析型分布式数据库为内核的全新数据计算平台,真正交付在PC机时代未能交付的大数据承诺。
PC时代数据的分析型数据库的代表性产品是封闭系统的TeraData和我和团队在Pivotal主导的开源的PC时代数据的*分析*型数据库的代表性产品是封闭系统的TeraData和我与团队在Pivotal主导的开源数据库—Greenplum,但是两者都采用了类似的MPP(Massive Parellel Processing)架构。这个也不奇怪,因为两者都同时受限于PC架构。MPP以PC机为单位,通过如下图所示的组群方式来扩展存储和计算。假设一个宽表有3亿条记录,MPP尝试在每台PC机上的硬盘上分布1亿条记录。计算的时候3台机器同时并行计算,理论上最高可以把计算时间降低到单机部署的1/3。
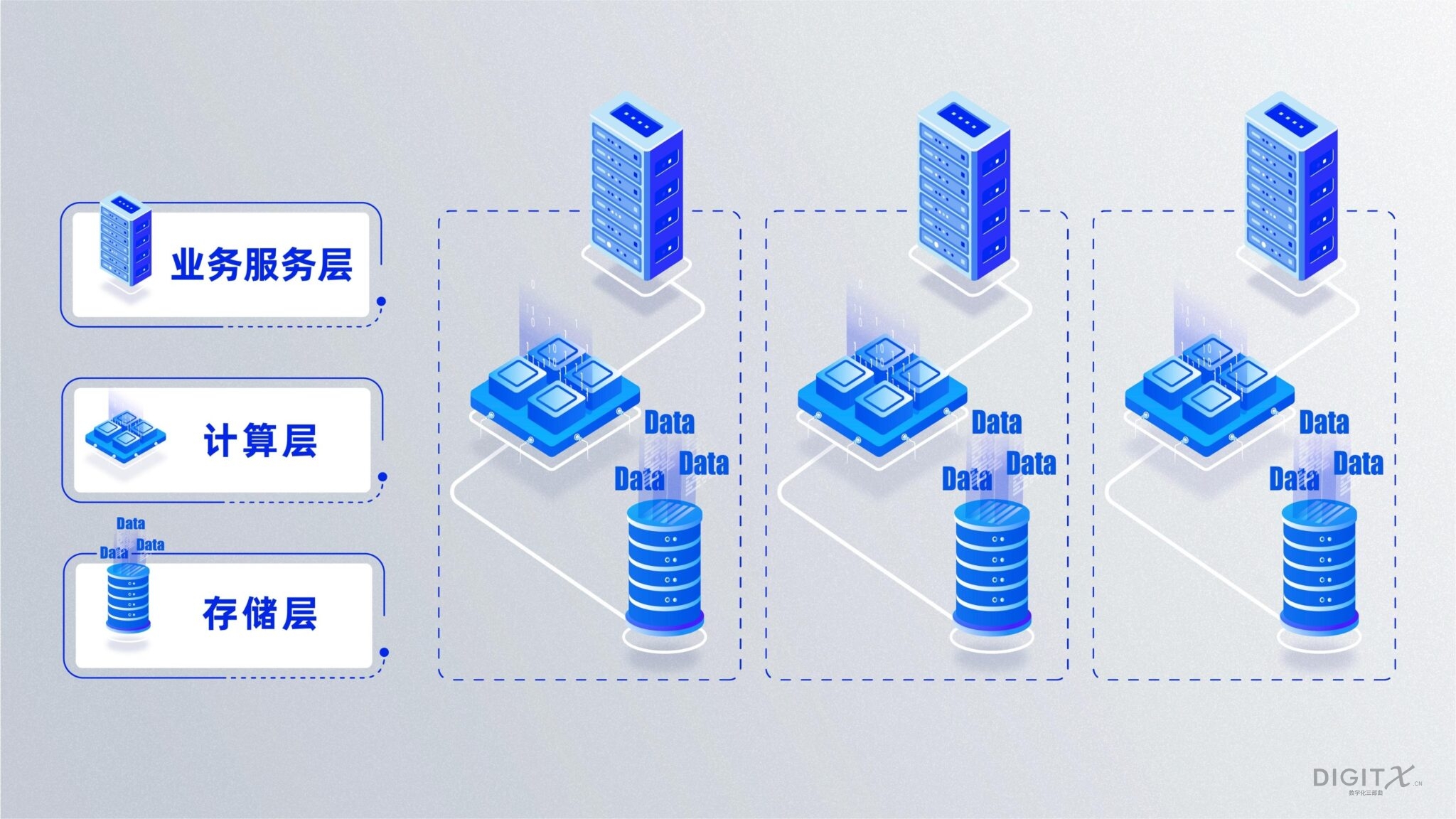
当用户需要更大的计算或者存储的时候,可以在水平方向加入第四台、第五台PC机。按理说,PC时代的分析型数据库也可以达到数据集中并为应用所共享的目标,为何在客户的实际场景中最终还是分为若干个集群而走向数据孤岛?简单来说,MPP的水平“扩展”能力和实际上的“静态”项目实施是矛盾的。“扩展”理论上是和时间关联的一个概念,而基于PC机的MPP设计前提并不是“时间的朋友”。首先,在扩容的时候有些客户只需要更大的存储硬盘,有些客户只需要更大的计算能力,但是基于PC结构的MPP要求用户必须以PC为单位同时购买存储和计算。这个听上去还能容忍,只是浪费了一点。其次,扩容要求一般在产品运行一段时间后才有,而因为摩尔定理市场上通常有更大密度的磁盘和更大算力的CPU,但是MPP的架构要求新增的PC机和之前的PC机是一样的老配置,不然任何一个集群的短板效应就是前面的老机器的能力。也就说摩尔定理不管多厉害,MPP集群拿老机器的存储和性能来一刀切而取低值。所以客户在购买新机器的时候,就忍不住另起炉灶,新建一个集群。我们经常发现:大的客户里面有10来个不同的集群,原本设想的大数据目标变成了10多个数据孤岛,有效地“阻止”了用户实现大数据目标,并让用户的最高领导层怀疑人生:“大数据并没有交付它的承诺”。最后,即使是那些在大数据领域食髓知味的用户,他们对一类脉冲式场景(例如双十一)也是望而生畏。他们当天可能需要100倍的算力来支持这类场景要求,PC结构的MPP迫使他们不得不投入100倍的机器,并且只为一年365天中的这一天。所以在实际场景,甲方不得不放弃这种脉冲式的数据计算机会。然而,所有的套利机会几乎都是脉冲式的,这种基于PC的MPP技术可以说是有效地“阻止”了让科技去快速抹平套利从而提高市场效率。
基于云计算架构的πCloudDB(不方便输入希腊字母的可以用罗马字符写作”PieCloudDB Database”)的弹性并行计算,则完美地解决上述基于PC的传统MPP的缺陷。在πCloudDB,存储和计算各自作为两个独立变量,各自在云端弹性伸缩。如下图所示,πCloudDB的用户可以在云端传输海量数据量,云中的存储(通常是S3对象存储)也会随之自动增加,这个伸展过程对于用户来说是完全透明不可见的。如果用户需要更大的算力,只需开启更多的虚拟机或者容器,πCloudDB会瞬间扩容。在用户完成脉冲计算以后,可以关闭和缩小计算的集群,从而节约在云中的计算费用。

存储和计算分离的云原生数据库的部署结构
更让人兴奋的是,πCloudDB允许用户运用云中数据同时开启多个集群进行数据计算。假设航空公司的订票系统已经开启一个3节点的集群对数据进行分析,他们的会员系统可以再开启4个节点的集群对数据进行计算,依次类推,他们可以随时随地地开启任何数量节点的集群进行新应用的数据计算。在这样一个系统中,用户会持续将所有数据在云中存储,为已有的应用和未来的应用真正实现数据共享,πCloudDB从而帮助用户真正实现大数据梦想(Big Data Promises finally Come True)。
组织和使命:从毕达哥拉斯派到哥廷根再到拓数派
πCloudDB是典型的拓数派在底层的数据计算的一个硬核科技创新范例。相比自顶向下的商业模式驱动的应ΠCloudDB是典型的拓数派在底层的数据计算的一个硬核科技创新范例。相比自顶向下的商业模式驱动的应用创新,拓数派采用的是认知拓展的最底层科技创新。这样的创新需要在一个高尚的使命上,集聚行业顶级人才,并对齐大家的内在驱动力。回顾历史,在数据计算领域有两个机构在基础科技的突破上实现飞跃:20世纪上半叶,德国哥廷根大学在希尔伯特(David Hilbert)的倡导下提出了形式化数学,启发了图灵构造计算机的概念模型和冯诺依曼构造存储计算机。(因为二战,冯诺依曼等人从哥廷根迁移到了美国的普林斯顿高等研究院完成了物理计算机的构造。)20世纪下半叶,卡内基梅隆大学的司马贺(Herbert Simon)利用符号计算来模拟人类智能,创建了世界闻名的CMU计算机学院并将之建设成为人工智能的先驱。拓数派把自己的使命定义成为“Data Computing for New Discoveries”,希望在中国建立可以跻身世界数据计算领域的顶级机构,推动数字文明走向数据计算时代。因此,在拓数派,πCloudDB作为云原生数据库只是第一阶段的产品呈现,而产品背后的数据计算的使命,使得我们聚拢了国内北大、清华、中科大少年班、南开、港中文、港理工等名校和海外CMU和Leuven(鲁汶大学)等名校人才;融合了来自Pivotal,Oracle,IBM等海外知名公司和腾讯、阿里巴巴、京东、快手等国内知名公司的专家;吸引了有奥赛奖牌背景的基础科学学者。我们把合伙人平台取名“毕达哥拉斯派”和“哥廷根”,表达了我们在研发产品的同时,平行升级自己的组织,使其成为立身中国并跻身世界前沿的数据计算机构。

感谢我们的投资方、着眼未来的客户和一起致力于基础科技创新的政府和学术机构所提供的高于经济收益为目标的支持。并感谢一路支持我们在数字文明的三部曲的不断探索的粉丝、社区用户和亲朋好友们。
用最真诚完美的行动回馈最优质的理想!